library(tidyverse) # datahåndtering, grafikk og glimpse()
library(rsample) # for å dele data i training og testing
library(pROC) # Beregne ROC-curve
library(caret) # Funksjonen confusionMatrix()3 Logistisk regresjon
I dette kapittelt skal vi bruke følgende pakker:
3.1 Empirisk eksempel: Kategorisk utfall
Som eksempel bruker vi et datasettet Attrition. Dette er et datasett over arbeidstakere i en bedrift der utfallsvariabelen er om arbeidstakeren slutter i jobben eller ikke.
For arbeidsgivere kan det være kostbart med endringer i staben. Arbeidstakere som slutter tar med seg erfaring og kompetanse, og nye arbeidstakere må læres opp. Arbeidsgiver bør derfor generelt legge til rette for at arbeidstakere ønsker å bli værende, men det kan også være aktuelt med mer målrettede tiltak. Når en arbeidstaker har fått et nytt jobbtilbud kan det være for sent. Hvis man derimot kan komme i forkjøpet kan man kanskje gjøre noe før vedkommende går til det skrittet å søke ny jobb. Hvis man kunne predikere hvem som kommer til å slutte kunne man altså gjort tiltak i forkant.1
Først leser vi inn datasettet. Deretter kan vi se på innholdet med glimpse():
attrition <- readRDS("data/attrition.rds")
glimpse(attrition)Rows: 1,470
Columns: 32
$ Age <int> 41, 49, 37, 33, 27, 32, 59, 30, 38, 36, 35, 2…
$ Attrition <fct> Yes, No, Yes, No, No, No, No, No, No, No, No,…
$ BusinessTravel <fct> Travel_Rarely, Travel_Frequently, Travel_Rare…
$ DailyRate <int> 1102, 279, 1373, 1392, 591, 1005, 1324, 1358,…
$ Department <fct> Sales, Research & Development, Research & Dev…
$ DistanceFromHome <int> 1, 8, 2, 3, 2, 2, 3, 24, 23, 27, 16, 15, 26, …
$ Education <int> 2, 1, 2, 4, 1, 2, 3, 1, 3, 3, 3, 2, 1, 2, 3, …
$ EducationField <fct> Life Sciences, Life Sciences, Other, Life Sci…
$ EmployeeNumber <int> 1, 2, 4, 5, 7, 8, 10, 11, 12, 13, 14, 15, 16,…
$ EnvironmentSatisfaction <int> 2, 3, 4, 4, 1, 4, 3, 4, 4, 3, 1, 4, 1, 2, 3, …
$ Gender <fct> Female, Male, Male, Female, Male, Male, Femal…
$ HourlyRate <int> 94, 61, 92, 56, 40, 79, 81, 67, 44, 94, 84, 4…
$ JobInvolvement <int> 3, 2, 2, 3, 3, 3, 4, 3, 2, 3, 4, 2, 3, 3, 2, …
$ JobLevel <int> 2, 2, 1, 1, 1, 1, 1, 1, 3, 2, 1, 2, 1, 1, 1, …
$ JobRole <fct> Sales Executive, Research Scientist, Laborato…
$ JobSatisfaction <int> 4, 2, 3, 3, 2, 4, 1, 3, 3, 3, 2, 3, 3, 4, 3, …
$ MaritalStatus <fct> Single, Married, Single, Married, Married, Si…
$ MonthlyIncome <int> 5993, 5130, 2090, 2909, 3468, 3068, 2670, 269…
$ MonthlyRate <int> 19479, 24907, 2396, 23159, 16632, 11864, 9964…
$ NumCompaniesWorked <int> 8, 1, 6, 1, 9, 0, 4, 1, 0, 6, 0, 0, 1, 0, 5, …
$ OverTime <fct> Yes, No, Yes, Yes, No, No, Yes, No, No, No, N…
$ PercentSalaryHike <int> 11, 23, 15, 11, 12, 13, 20, 22, 21, 13, 13, 1…
$ PerformanceRating <int> 3, 4, 3, 3, 3, 3, 4, 4, 4, 3, 3, 3, 3, 3, 3, …
$ RelationshipSatisfaction <int> 1, 4, 2, 3, 4, 3, 1, 2, 2, 2, 3, 4, 4, 3, 2, …
$ StockOptionLevel <int> 0, 1, 0, 0, 1, 0, 3, 1, 0, 2, 1, 0, 1, 1, 0, …
$ TotalWorkingYears <int> 8, 10, 7, 8, 6, 8, 12, 1, 10, 17, 6, 10, 5, 3…
$ TrainingTimesLastYear <int> 0, 3, 3, 3, 3, 2, 3, 2, 2, 3, 5, 3, 1, 2, 4, …
$ WorkLifeBalance <int> 1, 3, 3, 3, 3, 2, 2, 3, 3, 2, 3, 3, 2, 3, 3, …
$ YearsAtCompany <int> 6, 10, 0, 8, 2, 7, 1, 1, 9, 7, 5, 9, 5, 2, 4,…
$ YearsInCurrentRole <int> 4, 7, 0, 7, 2, 7, 0, 0, 7, 7, 4, 5, 2, 2, 2, …
$ YearsSinceLastPromotion <int> 0, 1, 0, 3, 2, 3, 0, 0, 1, 7, 0, 0, 4, 1, 0, …
$ YearsWithCurrManager <int> 5, 7, 0, 0, 2, 6, 0, 0, 8, 7, 3, 8, 3, 2, 3, …Merk at det er en variabel vi helt sikkert ikke trenger, så vi sletter denne like gjerne med en gang: EmployeeNumber er et løpenummer for person. Siden det er et 1:1 forhold mellom dette og utfallsvariabelen, så bør den tas ut. Vi lager også en numerisk versjon av utfallsvariabelen som vi trenger for plotting.
attrition <- attrition %>%
select(- EmployeeNumber) %>%
mutate(Attrition.num = as.numeric(Attrition == "Yes"))
glimpse(attrition)Rows: 1,470
Columns: 32
$ Age <int> 41, 49, 37, 33, 27, 32, 59, 30, 38, 36, 35, 2…
$ Attrition <fct> Yes, No, Yes, No, No, No, No, No, No, No, No,…
$ BusinessTravel <fct> Travel_Rarely, Travel_Frequently, Travel_Rare…
$ DailyRate <int> 1102, 279, 1373, 1392, 591, 1005, 1324, 1358,…
$ Department <fct> Sales, Research & Development, Research & Dev…
$ DistanceFromHome <int> 1, 8, 2, 3, 2, 2, 3, 24, 23, 27, 16, 15, 26, …
$ Education <int> 2, 1, 2, 4, 1, 2, 3, 1, 3, 3, 3, 2, 1, 2, 3, …
$ EducationField <fct> Life Sciences, Life Sciences, Other, Life Sci…
$ EnvironmentSatisfaction <int> 2, 3, 4, 4, 1, 4, 3, 4, 4, 3, 1, 4, 1, 2, 3, …
$ Gender <fct> Female, Male, Male, Female, Male, Male, Femal…
$ HourlyRate <int> 94, 61, 92, 56, 40, 79, 81, 67, 44, 94, 84, 4…
$ JobInvolvement <int> 3, 2, 2, 3, 3, 3, 4, 3, 2, 3, 4, 2, 3, 3, 2, …
$ JobLevel <int> 2, 2, 1, 1, 1, 1, 1, 1, 3, 2, 1, 2, 1, 1, 1, …
$ JobRole <fct> Sales Executive, Research Scientist, Laborato…
$ JobSatisfaction <int> 4, 2, 3, 3, 2, 4, 1, 3, 3, 3, 2, 3, 3, 4, 3, …
$ MaritalStatus <fct> Single, Married, Single, Married, Married, Si…
$ MonthlyIncome <int> 5993, 5130, 2090, 2909, 3468, 3068, 2670, 269…
$ MonthlyRate <int> 19479, 24907, 2396, 23159, 16632, 11864, 9964…
$ NumCompaniesWorked <int> 8, 1, 6, 1, 9, 0, 4, 1, 0, 6, 0, 0, 1, 0, 5, …
$ OverTime <fct> Yes, No, Yes, Yes, No, No, Yes, No, No, No, N…
$ PercentSalaryHike <int> 11, 23, 15, 11, 12, 13, 20, 22, 21, 13, 13, 1…
$ PerformanceRating <int> 3, 4, 3, 3, 3, 3, 4, 4, 4, 3, 3, 3, 3, 3, 3, …
$ RelationshipSatisfaction <int> 1, 4, 2, 3, 4, 3, 1, 2, 2, 2, 3, 4, 4, 3, 2, …
$ StockOptionLevel <int> 0, 1, 0, 0, 1, 0, 3, 1, 0, 2, 1, 0, 1, 1, 0, …
$ TotalWorkingYears <int> 8, 10, 7, 8, 6, 8, 12, 1, 10, 17, 6, 10, 5, 3…
$ TrainingTimesLastYear <int> 0, 3, 3, 3, 3, 2, 3, 2, 2, 3, 5, 3, 1, 2, 4, …
$ WorkLifeBalance <int> 1, 3, 3, 3, 3, 2, 2, 3, 3, 2, 3, 3, 2, 3, 3, …
$ YearsAtCompany <int> 6, 10, 0, 8, 2, 7, 1, 1, 9, 7, 5, 9, 5, 2, 4,…
$ YearsInCurrentRole <int> 4, 7, 0, 7, 2, 7, 0, 0, 7, 7, 4, 5, 2, 2, 2, …
$ YearsSinceLastPromotion <int> 0, 1, 0, 3, 2, 3, 0, 0, 1, 7, 0, 0, 4, 1, 0, …
$ YearsWithCurrManager <int> 5, 7, 0, 0, 2, 6, 0, 0, 8, 7, 3, 8, 3, 2, 3, …
$ Attrition.num <dbl> 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, …Del datasettet i to deler. Vi trekker tilfeldig 70% og legger dette i datasettet training. Resten legges i testing.
set.seed(426)
attrition_split <- initial_split(attrition)
training <- training(attrition_split)
testing <- testing(attrition_split)Sjekk at antallet i hvert datasett summeres til totalen
nrow(attrition)[1] 1470nrow(training)[1] 1102nrow(testing)[1] 368Andelen som slutter kan vi få med mean():
mean(training$Attrition.num)[1] 0.1533575Vi kan vise hvordan det å slutte i jobben varierer med f.eks. alder ved å beregne andel per verdi av alder.
training_p <- training %>%
group_by(Age) %>%
summarise(Attrition = mean(Attrition.num))
ggplot(training_p, aes(x=Age, y=Attrition))+
geom_point()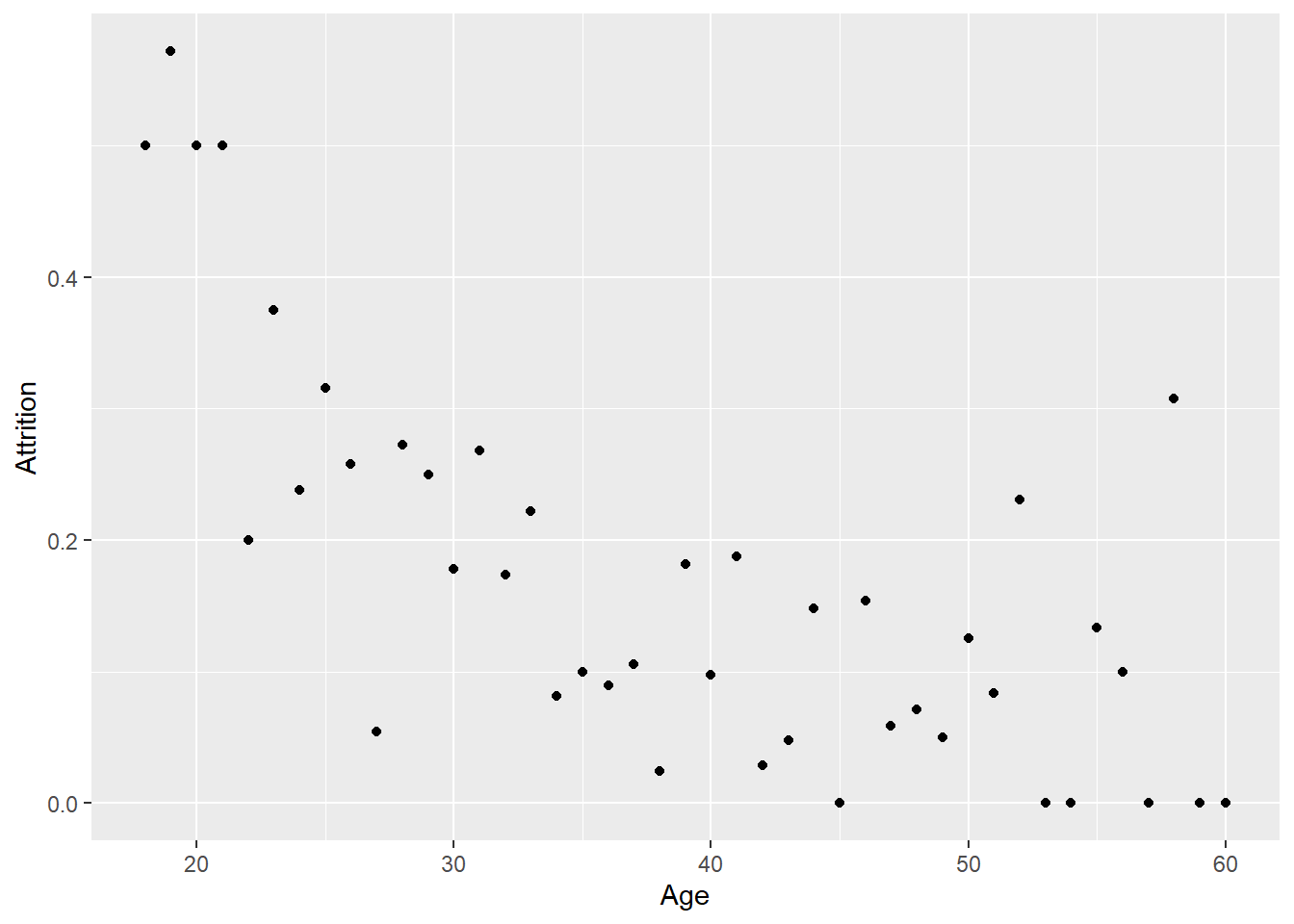
3.2 Estimere en sannsynlighet
Når utfallsvariabelen er binær (to verdier) kan man likevel bruke lineær regresjon. Det kalles da gjerne en lineær sannsynlighetsmodell.
lm_est <- lm(Attrition.num ~ Age , data = training)
summary(lm_est)
Call:
lm(formula = Attrition.num ~ Age, data = training)
Residuals:
Min 1Q Median 3Q Max
-0.28444 -0.18737 -0.14576 -0.06256 0.99292
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.409254 0.044335 9.231 < 2e-16 ***
Age -0.006934 0.001166 -5.948 3.65e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.355 on 1100 degrees of freedom
Multiple R-squared: 0.03116, Adjusted R-squared: 0.03027
F-statistic: 35.37 on 1 and 1100 DF, p-value: 3.652e-09Den viktigste ulempen med lineære sannsynlighetsmodeller er at modellen da kan predikere sannsynligheter lavere enn 0 og høyere enn 1. Når man er mest interessert i \(\beta\) er det ikke sikkert det er så nøye. Men når vi er interessert i \(\hat{y}\) kan det derimot være viktig.
3.3 Logistisk regresjon i R
Logistisk regresjon har det til felles med lineær regresjon at utfallet er en lineær spesifikasjon.
\[ log( \frac{\pi}{1-\pi}) = \alpha + \beta X \]
Venstresiden av ligningen kalles en logit, der \(\pi\) er en sannsynlighet. Uttrykket \(\frac{\pi}{(1-\pi)}\) er en odds, som er et forholdstall mellom sannsynligheten for at utfallet skjer mot sannsynligheten for det motsatte. Tolkningen av \(\beta\) er da en endring av odds på logaritisk skala. Hvis man eksponensierer \(\beta\) er den da tolkbar som en oddsrate.
Man kan regne om til sannsynligheter som er vesentlig enklere å forstå. Ligningen kan skrives om slik:
\[ \hat \pi = \frac{e^{\alpha + \beta X}}{1 + e^{\alpha + \beta X}} \]
En relativt enkel omregning av regresjonsresultatet gir altså en sannynlighet. Denne sannsynligheten kan vi da bruke til klassifikasjon hvis det er formålet med analysen. Hvis utfallsvariabelen har to kategorier, så er en nærliggende mulighet å klassifisere til den gruppen hver person mest sannsynlig tilhører. Altså: de som har \(\hat{\pi} = P(y = 1) > 0.5\) tilhører den ene gruppen og resten i den andre gruppen.
Her er et eksempel på hvordan estimere enkel logistisk regresjon i R:
est_logit <- glm(Attrition ~ Age, data = training, family = "binomial")
summary(est_logit)
Call:
glm(formula = Attrition ~ Age, family = "binomial", data = training)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.41516 0.36402 1.140 0.254
Age -0.06026 0.01050 -5.741 9.43e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 944.39 on 1101 degrees of freedom
Residual deviance: 907.48 on 1100 degrees of freedom
AIC: 911.48
Number of Fisher Scoring iterations: 5Vi kan sammenligne lineær og logistisk modell for å se forskjellen i predikert sannsynlighet. Den røde kurven er den lineære modellen og den blå er den logistiske:
testing <- testing %>%
mutate(prob_lm = predict(lm_est, newdata = testing, type = "response"),
prob_glm = predict(est_logit, newdata = testing, type = "response"))
ggplot(testing, aes(x = prob_lm)) +
geom_density(fill = "red", alpha = .3) +
geom_density(aes(x = prob_glm), fill = "blue", alpha = .3)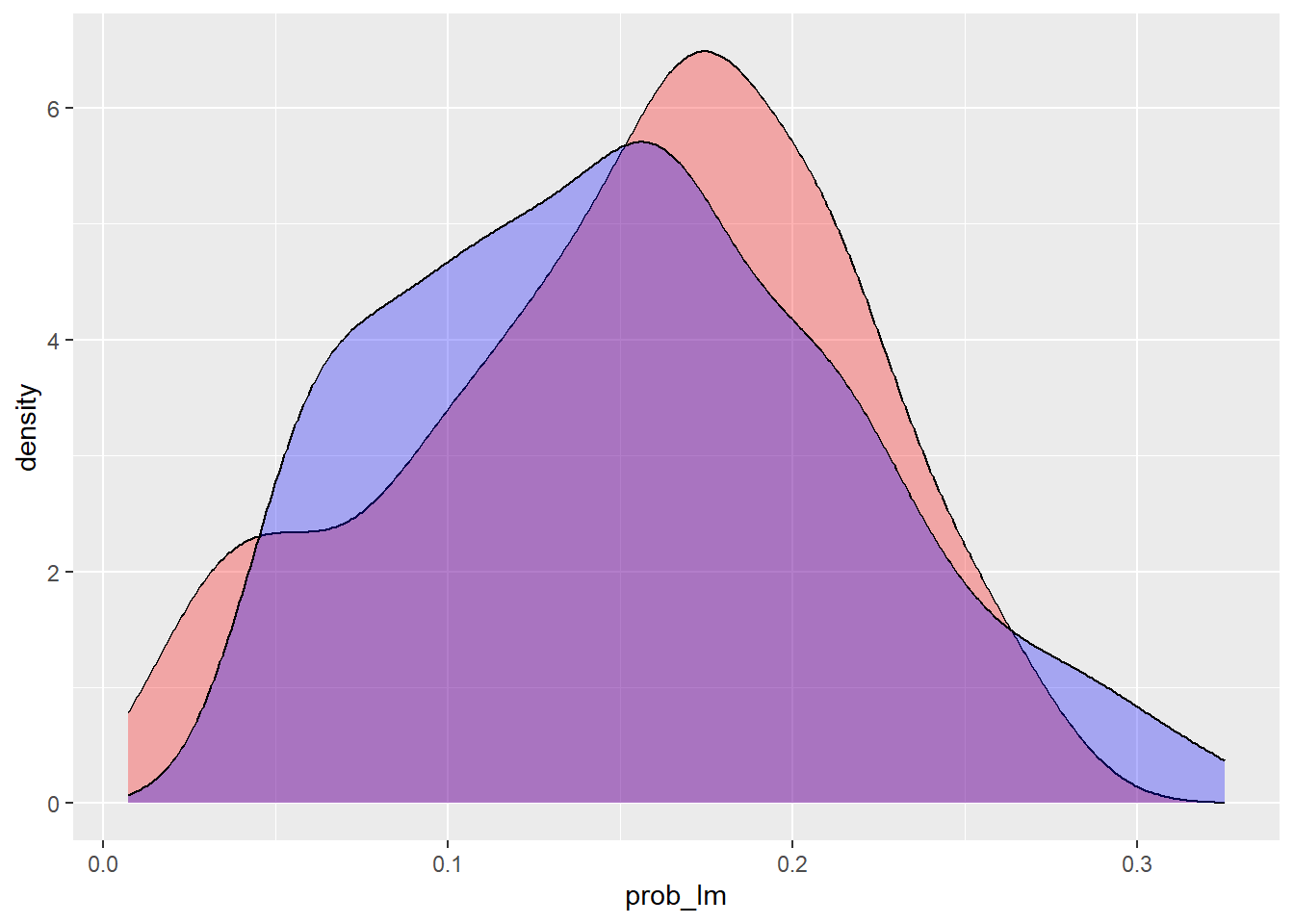
Forskjellen er som regel ikke så stor i midten av fordelingen, men den lineære modellen kan gi verdier utenfor 0-1-intervallet. For klassifikasjon spiller det sjelden noen stor rolle, men for å være korrekt bruker vi logistisk regresjon når utfallet er binært.
Hvordan plotte slike data? Bruk geom_jitter eller geom_point.
ggplot(training, aes(x=Age, y=Attrition.num))+
geom_jitter(height = .02, alpha=.3)+
stat_smooth(method="glm", method.args=list(family="binomial"), se=FALSE, col="red")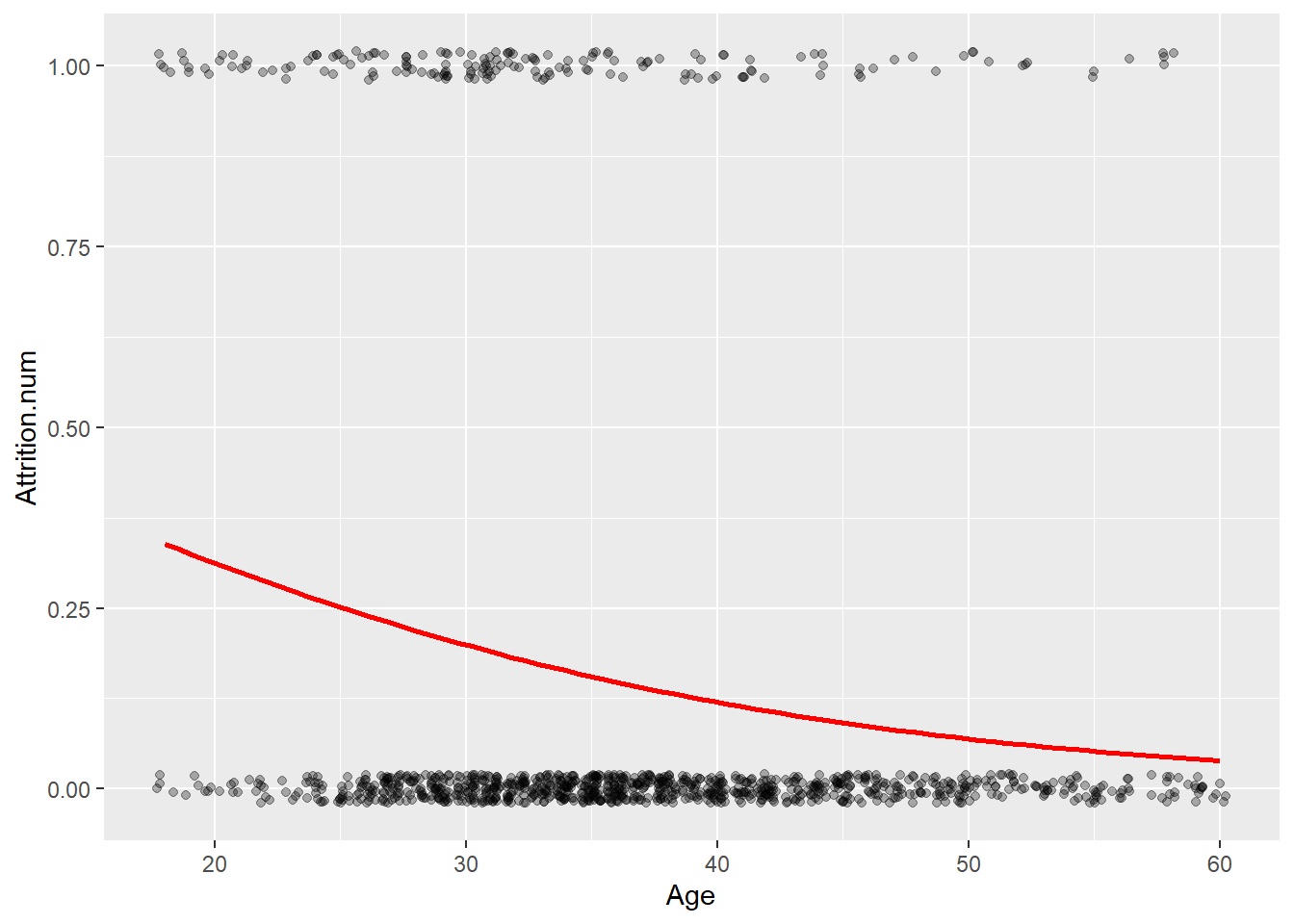
3.4 Prediksjon
Vi kan predikere med bruk av predict() som tidligere. Nå er det viktig å presisere type = "response" for å få sannsynligheter i stedet for log-odds.
attrition_pred <- training %>%
mutate(prob = predict(est_logit, type = "response"))3.4.1 ROC og AUC
For å vurdere hvor god prediksjonen er uavhengig av valg av cut-off bruker vi ROC-kurven (Receiver Operating Characteristic). ROC-kurven viser sammenhengen mellom sensitivity (andelen sanne positive) og 1-specificity (andelen falske positive) for alle mulige verdier av cut-off. En modell som predikerer perfekt vil gi en kurve som går rett opp og deretter bort til høyre. En modell som gjetter tilfeldig vil ligge langs den diagonale grå linjen.
ROC <- roc( attrition_pred$Attrition, attrition_pred$prob )Setting levels: control = No, case = YesSetting direction: controls < casesdf <- data.frame(Sensitivity = ROC$sensitivities,
Specificity = ROC$specificities)
ggplot(df, aes(y = Sensitivity, x= (1-Specificity))) +
geom_line() +
geom_abline(intercept = 0, slope = 1, col = "gray")+
coord_equal()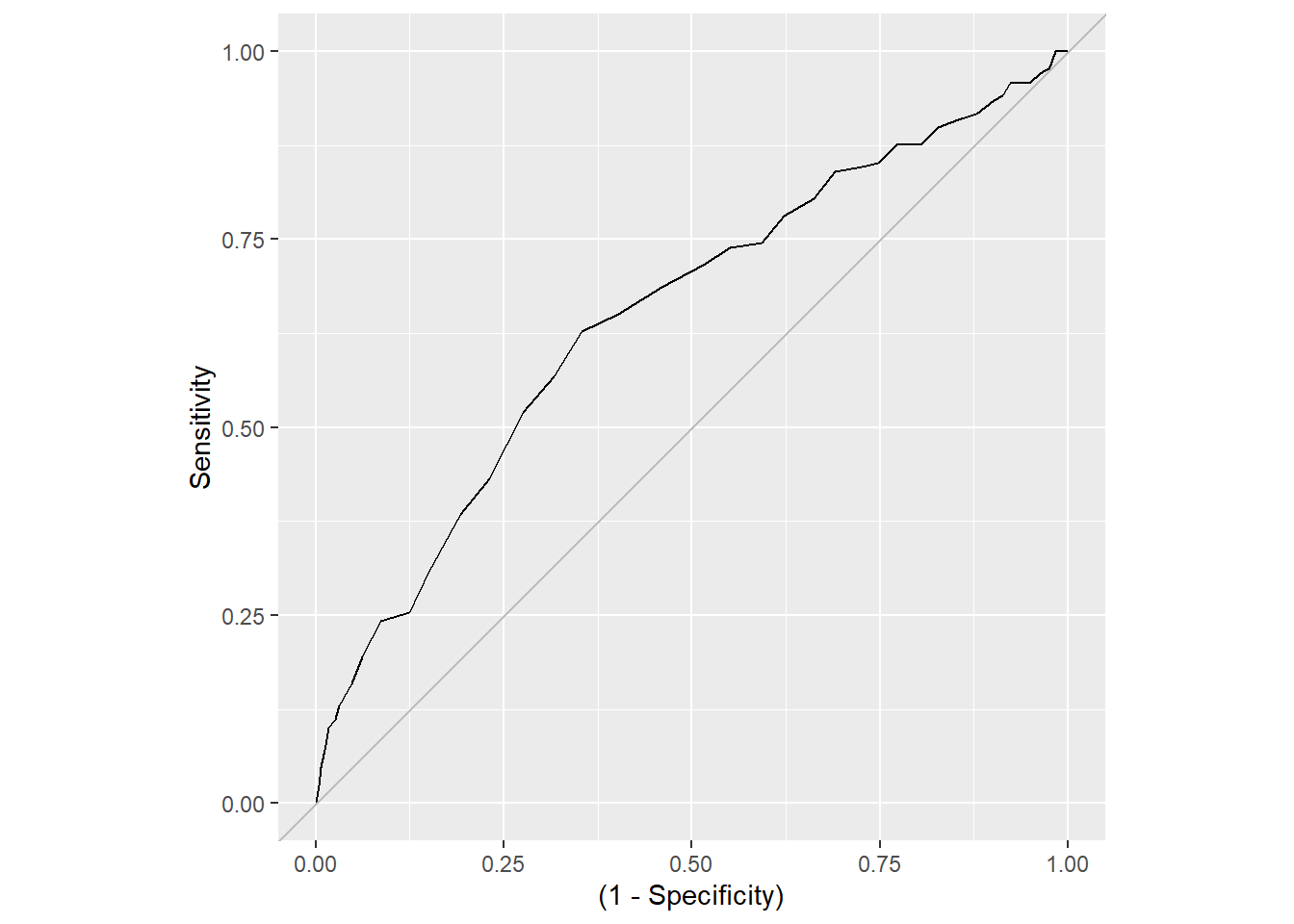
Arealet under ROC-kurven (AUC) gir et enkelt tall som oppsummerer modellens prediksjonsevne. AUC varierer mellom 0.5 (tilfeldig gjetting) og 1.0 (perfekt prediksjon). For den enkle modellen er AUC 0.65.
3.5 Multippel logistisk regresjon
Vi kan estimere en multippel regresjon på tilsvarende måte som for lineær regresjon ved å legge til flere variable eller angi å bruke samtlige variable i datasettet med Attrition ~ ..
est_multlogit <- glm(Attrition ~ ., data = training[, !names(training) %in% "Attrition.num"], family = "binomial")
summary(est_multlogit)
Call:
glm(formula = Attrition ~ ., family = "binomial", data = training[,
!names(training) %in% "Attrition.num"])
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -1.035e+01 4.542e+02 -0.023 0.981824
Age -3.565e-02 1.628e-02 -2.190 0.028495 *
BusinessTravelTravel_Frequently 1.628e+00 4.675e-01 3.482 0.000498 ***
BusinessTravelTravel_Rarely 8.988e-01 4.267e-01 2.106 0.035192 *
DailyRate -3.117e-04 2.648e-04 -1.177 0.239034
DepartmentResearch & Development 1.203e+01 4.542e+02 0.026 0.978861
DepartmentSales 1.239e+01 4.542e+02 0.027 0.978244
DistanceFromHome 4.145e-02 1.300e-02 3.189 0.001428 **
Education -1.376e-02 1.039e-01 -0.132 0.894627
EducationFieldLife Sciences -8.013e-01 1.027e+00 -0.781 0.435083
EducationFieldMarketing -2.129e-01 1.076e+00 -0.198 0.843199
EducationFieldMedical -8.617e-01 1.028e+00 -0.838 0.401983
EducationFieldOther -7.977e-01 1.098e+00 -0.727 0.467345
EducationFieldTechnical Degree 1.370e-01 1.048e+00 0.131 0.896014
EnvironmentSatisfaction -4.957e-01 9.942e-02 -4.986 6.18e-07 ***
GenderMale 2.156e-01 2.149e-01 1.003 0.315665
HourlyRate -3.532e-03 5.385e-03 -0.656 0.511937
JobInvolvement -5.422e-01 1.452e-01 -3.734 0.000189 ***
JobLevel 1.864e-02 3.817e-01 0.049 0.961047
JobRoleHuman Resources 1.308e+01 4.542e+02 0.029 0.977028
JobRoleLaboratory Technician 1.531e+00 5.543e-01 2.762 0.005746 **
JobRoleManager -1.451e+00 1.269e+00 -1.144 0.252636
JobRoleManufacturing Director -3.131e-01 6.086e-01 -0.514 0.606923
JobRoleResearch Director -2.440e+00 1.244e+00 -1.961 0.049843 *
JobRoleResearch Scientist 3.417e-01 5.694e-01 0.600 0.548406
JobRoleSales Executive 3.595e-01 1.603e+00 0.224 0.822589
JobRoleSales Representative 1.518e+00 1.650e+00 0.920 0.357555
JobSatisfaction -3.169e-01 9.701e-02 -3.267 0.001087 **
MaritalStatusMarried 3.453e-01 3.135e-01 1.101 0.270697
MaritalStatusSingle 8.690e-01 4.056e-01 2.143 0.032140 *
MonthlyIncome 8.613e-05 9.875e-05 0.872 0.383105
MonthlyRate 8.922e-06 1.482e-05 0.602 0.547277
NumCompaniesWorked 1.721e-01 4.623e-02 3.722 0.000198 ***
OverTimeYes 1.877e+00 2.296e-01 8.174 2.98e-16 ***
PercentSalaryHike -6.102e-02 4.687e-02 -1.302 0.192953
PerformanceRating 6.920e-01 4.794e-01 1.443 0.148883
RelationshipSatisfaction -3.738e-01 9.827e-02 -3.804 0.000142 ***
StockOptionLevel -3.059e-01 1.810e-01 -1.690 0.091064 .
TotalWorkingYears -6.605e-02 3.580e-02 -1.845 0.065052 .
TrainingTimesLastYear -2.129e-01 8.533e-02 -2.495 0.012582 *
WorkLifeBalance -2.150e-01 1.456e-01 -1.476 0.139869
YearsAtCompany 6.067e-02 4.877e-02 1.244 0.213537
YearsInCurrentRole -9.948e-02 5.569e-02 -1.786 0.074038 .
YearsSinceLastPromotion 2.052e-01 5.182e-02 3.960 7.50e-05 ***
YearsWithCurrManager -1.866e-01 6.072e-02 -3.073 0.002122 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 944.39 on 1101 degrees of freedom
Residual deviance: 619.99 on 1057 degrees of freedom
AIC: 709.99
Number of Fisher Scoring iterations: 143.5.1 ROC og AUC
For å beregne ROC og AUC gjør vi tilsvarende som over med predict og angi type respons.
attrition_pred <- training %>%
mutate(prob = predict(est_multlogit, type = "response"))Funksjonen roc() gjør utregningene som trengs for ROC-kurven basert på observert utfall og predikerte sannsynligheter (Hsieh 2008).
OBS! Man må man angi data som første argument i funksjonen roc(), deretter observerte utfall og til sist predikert sannsynlighet. Rekkefølgen er viktig!
ROC <- roc(attrition_pred, Attrition, prob)Setting levels: control = No, case = YesSetting direction: controls < casesdf <- data.frame(Sensitivity = ROC$sensitivities,
Specificity = ROC$specificities)
ggplot(df, aes(y = Sensitivity, x= (1-Specificity))) +
geom_line() +
geom_abline(intercept = 0, slope = 1, col = "gray")+
coord_equal()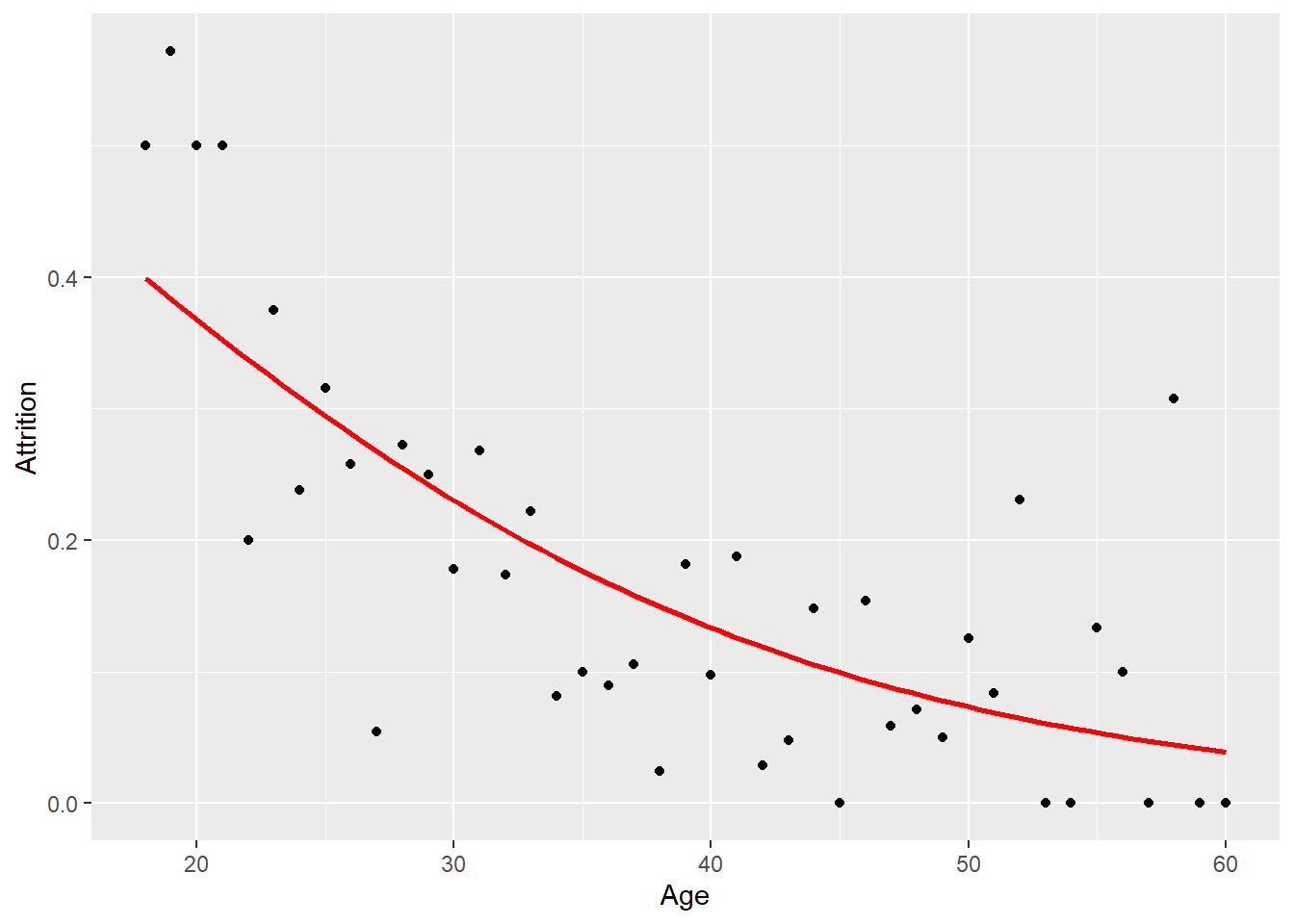
Vi kan da få rapportert arealet under kurven med auc() slik:
auc(ROC)Area under the curve: 0.8675Når arealet under kurven (AUC) er 0.867 er det vesentlig bedre prediksjon enn den enkle modellen.
3.6 Testing-data
Ovenfor er øvelsen gjort på training-data, men vi må sjekke på testing-dataene.
For å beregne ROC og AUC gjør vi tilsvarende som over med predict, men nå er det viktig å angi newdata = ... slik at prediksjonen gjøres på riktig datasett.
attrition_test <- testing %>%
mutate(prob = predict(est_multlogit, newdata = testing, type = "response"))ROC_test <- roc(attrition_test, Attrition, prob)Setting levels: control = No, case = YesSetting direction: controls < casesdf <- data.frame(Sensitivity = ROC_test$sensitivities,
Specificity = ROC_test$specificities)
ggplot(df, aes(y = Sensitivity, x= (1-Specificity))) +
geom_line() +
geom_abline(intercept = 0, slope = 1, col = "gray")+
coord_equal()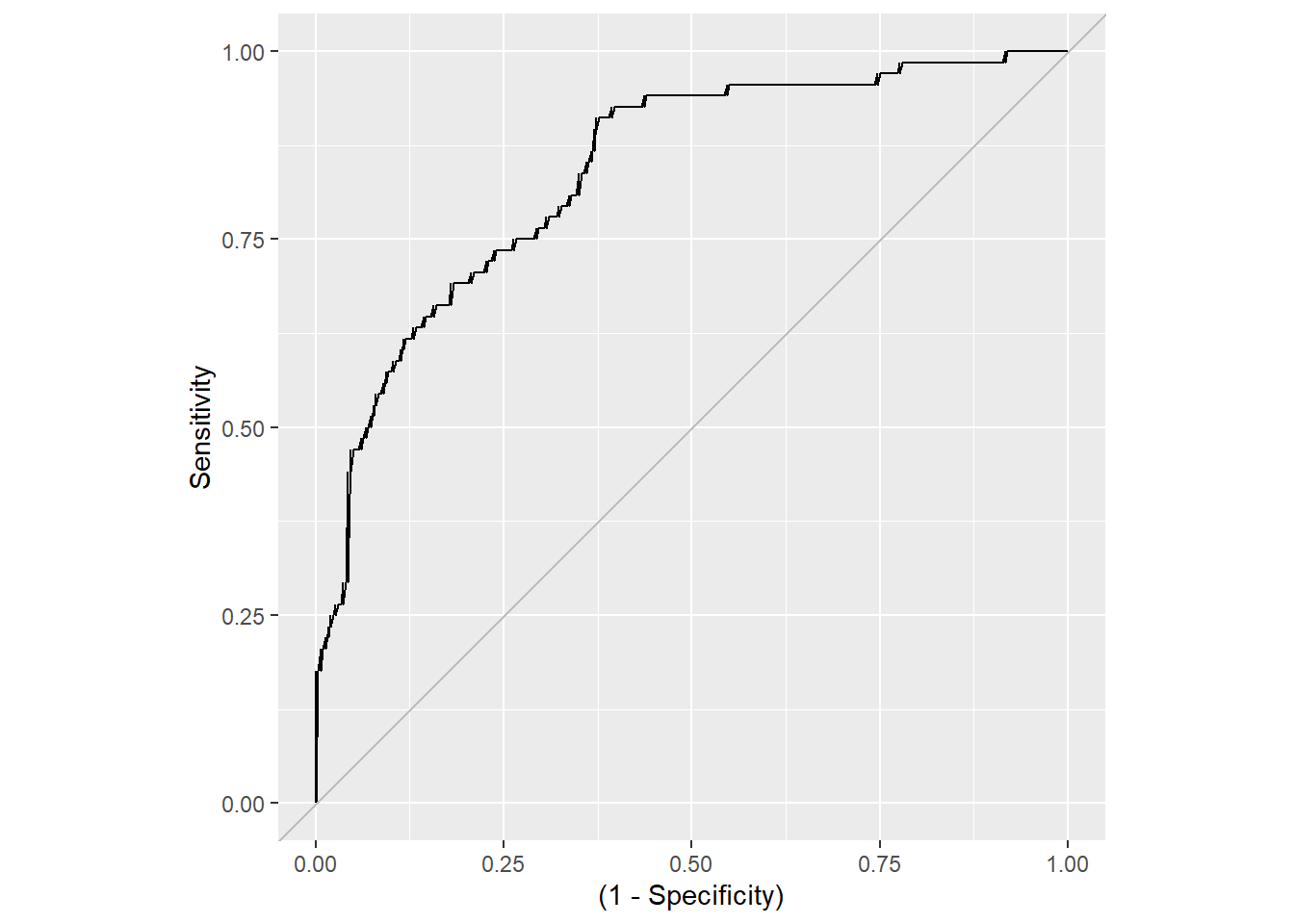
Vi kan da få rapportert arealet under kurven med auc() slik:
auc(ROC_test)Area under the curve: 0.8397Når arealet under kurven (AUC) er 0.84. Kanskje litt overraskende, men dette like godt som for på training dataene. AUC er altså arealet under kurven. Litt ulik form kan i prinsippet ha samme areal.
3.7 Klassifikasjon
Men for et handlingsvalg må vi gjøre faktisk klassifisering. Det vi har estimert så langt er bare en sannsynlighet. Selve klassifiseringen krever at man tar et aktivt valg om en cut-off for hvem man tror faktisk slutter. La oss først se på fordelingen av predikerte sannsynligheter:
ggplot(attrition_test, aes(x = prob)) +
geom_histogram()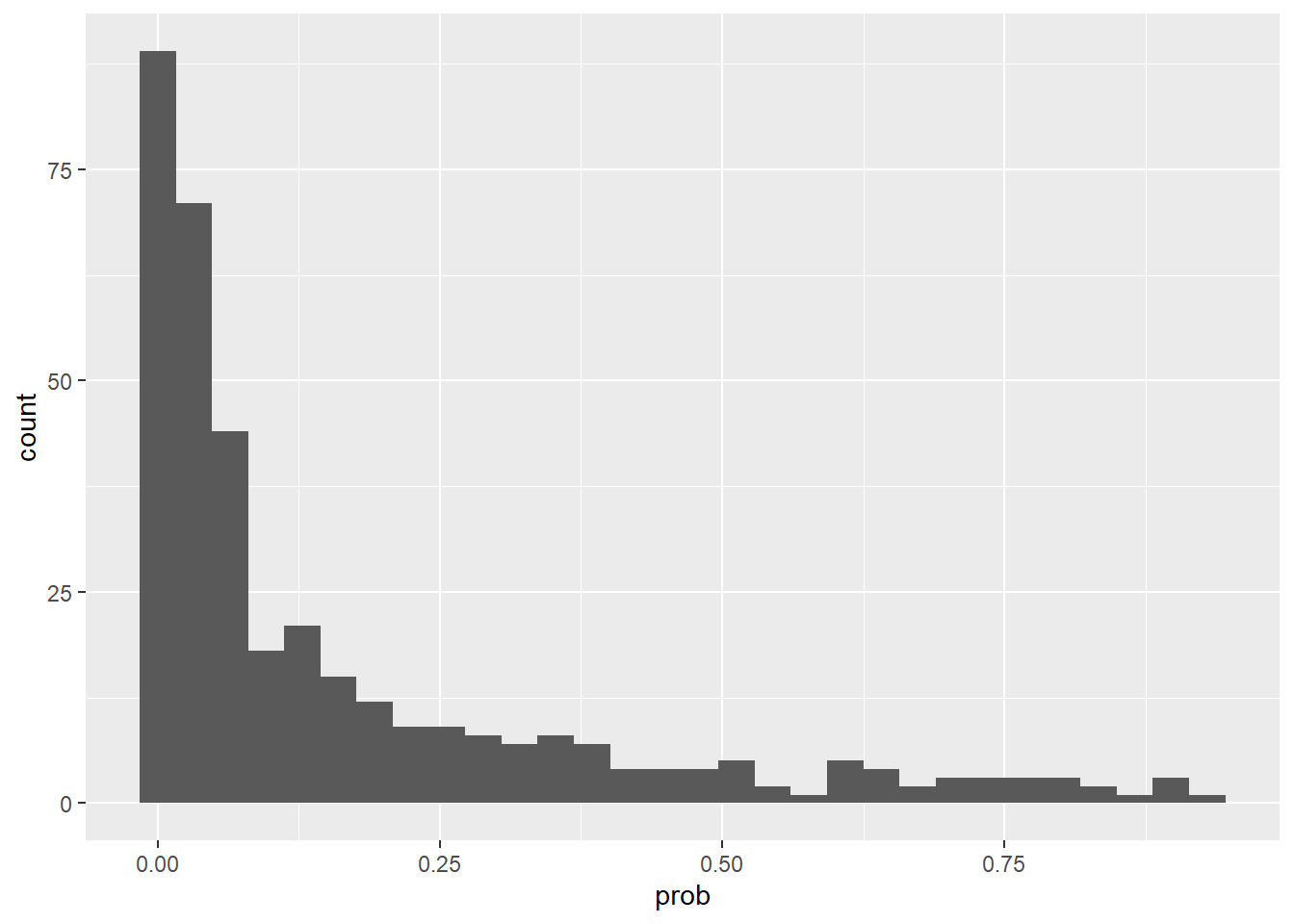
De aller fleste har lav predikert sannsynlighet for å slutte. Det er som forventet siden de fleste faktisk ikke slutter. Spørsmålet er nå: ved hvilken sannsynlighet skal vi si at noen er i faresonen?
Vi kan bestemme oss for at et rimelig cut-off er 50/50, altså med sannsynlighet 0.5. Her gjøres en klassifisering for testing-datasettet, og lager en krysstabell med den klassifiserte etter prediksjon mot observert utfall. En slik krysstabell kalles altså en confusion matrix.
attrition_test <- attrition_test %>%
mutate(attrition_class = as.factor(ifelse(prob < .5, "No", "Yes")))
tab <- attrition_test %>%
select(attrition_class, Attrition) %>%
table()
tab Attrition
attrition_class No Yes
No 287 45
Yes 13 233.7.1 Confusion matrix
Fra pakken caret er det en funksjon for confusion matrix som regner ut masse greier for oss. Merk at positive = "Yes" angir hva som er utfallsverdi av interesse.
confusionMatrix(reference = attrition_test$Attrition, attrition_test$attrition_class, positive = "Yes")Confusion Matrix and Statistics
Reference
Prediction No Yes
No 287 45
Yes 13 23
Accuracy : 0.8424
95% CI : (0.8011, 0.8781)
No Information Rate : 0.8152
P-Value [Acc > NIR] : 0.09925
Kappa : 0.3605
Mcnemar's Test P-Value : 4.691e-05
Sensitivity : 0.33824
Specificity : 0.95667
Pos Pred Value : 0.63889
Neg Pred Value : 0.86446
Prevalence : 0.18478
Detection Rate : 0.06250
Detection Prevalence : 0.09783
Balanced Accuracy : 0.64745
'Positive' Class : Yes
3.8 Hvor feil kan man ta?
I klassifiseringen over er det gjort et klart valg for hvem man tror faktisk vil slutte i jobben eller ikke. Det er selvsagt slik at noen er mer sannsynlige vil slutte enn andre, men ingen har 0 sannsynlighet. Ingen har 1 heller, for den saks skyld. Det er altså usikkerhet. Men hvis vi skal gjøre et tiltak, så må vi ta det valget!
Hvis vi gjør klassifiseringen på 0.5 som over, så betyr jo det at vi synes begge feil er like viktige: Falske positive eller falske negative. Hvis det er et langt større problem at folk slutter enn at noen f.eks. får tilbud om goder eller ekstra oppfølging etc, så kan det hende cut-off skal settes lavere? Da får man flere sanne positive, men også flere feil. Det kan det jo være verd, men kommer jo an på hva konsekvensene. Vi kommer tilbake til dette, men test gjerne ut selv med ulik cut-off og se hvordan resultatene endrer seg.
Her kunne man jo også tenke seg at den gode lederen har en dialog med de ansatte og fanger opp deres frustrasjoner og behov slik at maskinell prediksjon ikke trengs. Det er jo også en form for prediksjon med kvalitative data! Så her er vi i en setting der dette ikke fungerer eller det er så store forhold at en kvalitativ tilnærming ikke er praktisk mulig eller noe sånt.↩︎