Temaet er maskinlæring generelt og datadrevne beslutninger. Vi kommer inn på flere av temaene som vil behandles grundigere gjennom kurset.
1.1 Noen innledende metodiske begrep
I standard samfunnsvitenskapelige metodekurs lærer man først og fremst teknikker for å beskrive data og statistisk inferens for å beskrive usikkerheten rundt estimatene. Avhengig av studiets øvrige design kan resultatene tolkes kausalt og/eller generalisere til en nærmere veldefinert populasjon (Berk 2016).
Usikkerhet beskrives typisk ved hjelp standardfeil, p-verdier og konfidensintervall tilhørende spesifikke statistiske tester. Dette innebærer at man bruker statistiske modeller for hvordan resultatene ville sett ut under spesifikke forutsetninger. Samplingfordelinger som normalfordelingen og en del andre tilsvarende fordelinger er derfor sentralt. De fleste teknikkene vi skal bruke i dette kurset er ikke statistiske modeller i samme forstand og det er ingen antakelser om samplingfordelinger. Standardfeil og konfidensintervall kan derfor ikke regnes ut. Usikkerhet og hvem resultatene gjelder for er også relevante for maskinlæring, men ikke helt på samme måte.
1.2 Forklaringer og prediksjoner
Vi er i liten grad interessert i regresjonskoeffisienter, \(\beta\), og tolkning av denne. Derimot er vi interessert i det predikerte utfallet \(\hat{y}_i\).
1.3 Overfitting: training og testing dataset
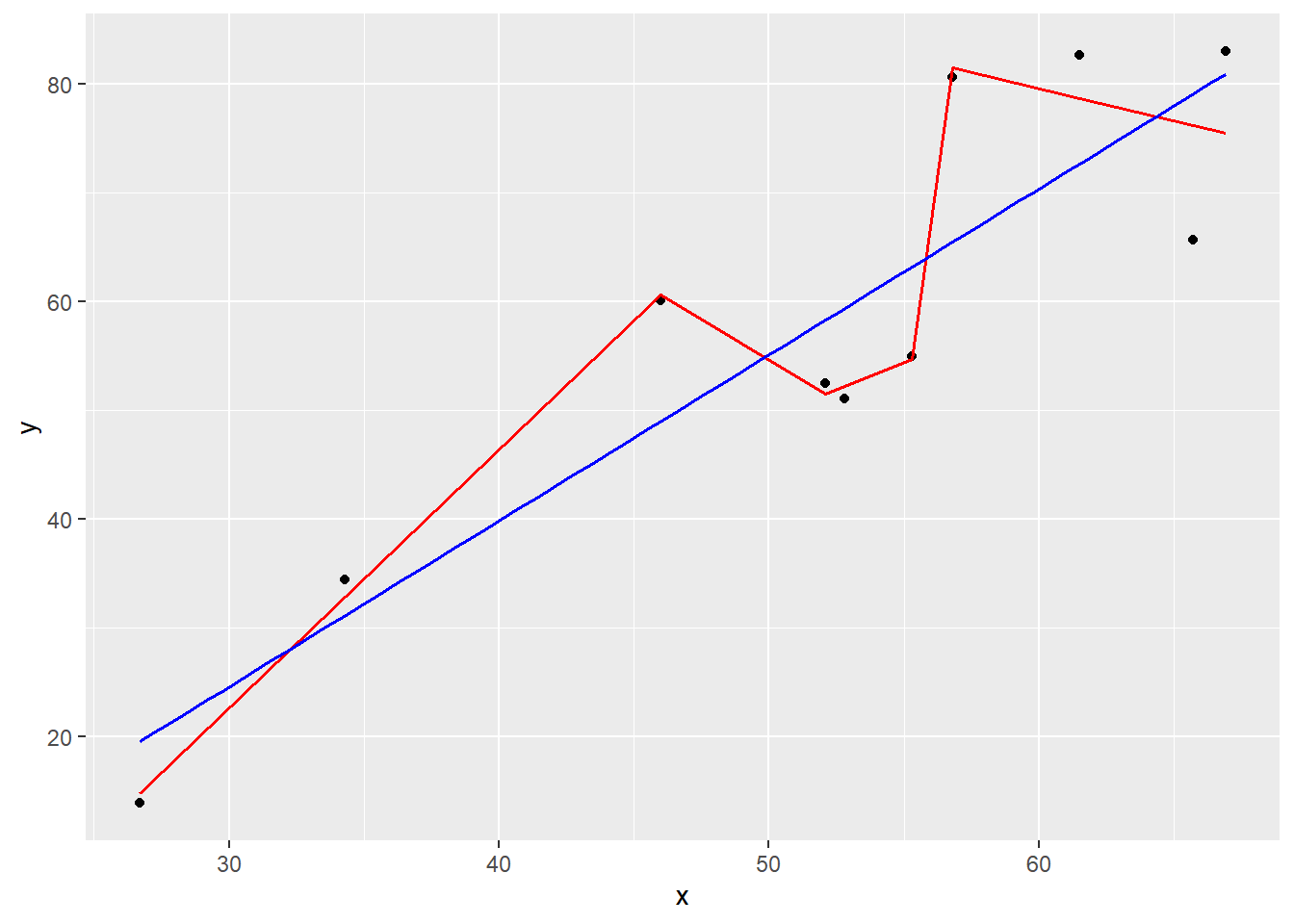
Når man tilpasser en statistisk modell eller algoritme til data så er det lett å tenke at modellen bør gjenspeile dataene så godt som mulig. Samtidig sies det ofte at modellene skal være så enkle som tilrådelig. En mer komplisert modell vil jo være i stand til å tilpasses dataene i større grad, så hvordan avveie dette?
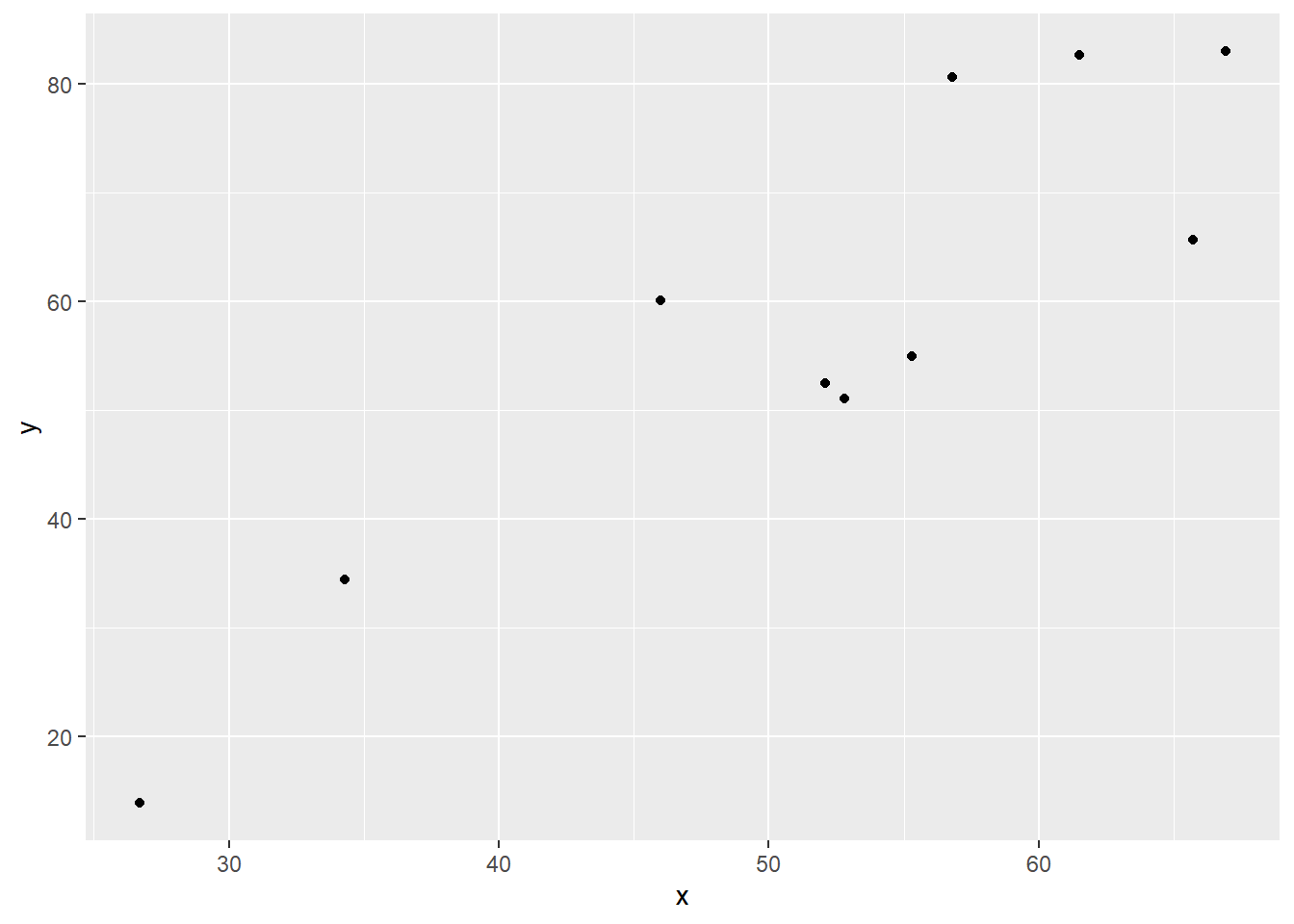
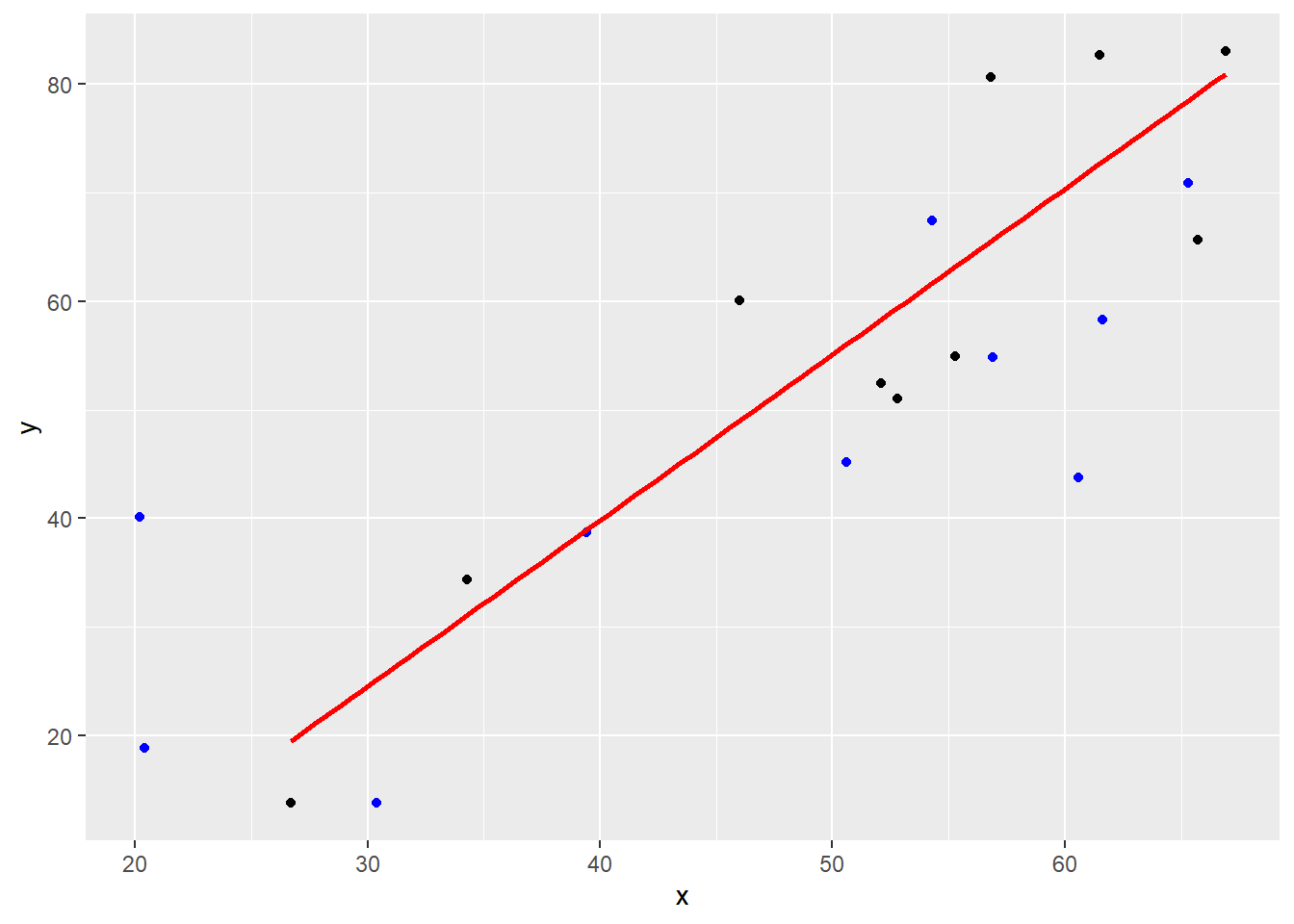
Spørsmålet nå er ikke hvor godt modellen passer til disse dataene, men hvordan den passer til nye data! Altså fremtidige data eller fremtidig situasjon. La oss si at vi har et datasett som kan plottes om følger:
I praksis kommer vi til å fokusere mest på klassifikasjon, som altså er når det vi predikerer er en kategorisk variabel. For nye personer vil vi da gjerne predikere hvilken kategori vedkommende tilhører. En variant av dette er å predikere en fremtidig handling (slutte i jobb, ikke betale tilbake lån, begå ny kriminalitet etc).
1.4.1 Confusion matrix: riktig og feil klassifisering
Når vi predikerer et kategorisk utfall er det gjerne ett av utfallene vi primært er interessert i. Disse kalles positive og de andre er negative. Dette har ingenting å gjøre med om utfallet er bra eller dårlig å gjøre. Å predikere en sykdom vil være positivt og å være frisk vil være negativt. Å ha tilbakefall til kriminalitet vil være positivt og lovlydig vil være negativt.
En positiv prediksjon kan da være korrekt eller feil, og disse kalles da henholdsvis sanne eller falske positive. Tilsvarende kan en negaitv prediksjon være sann eller falsk.
Predikert
Negativ
Positiv
Observert
Negativ
Sanne negative (TN)
Falske positive (FN)
Positiv
Falske negative (FN)
Sanne positive (TP)
1.4.2 Asymetriske kostnader
Å predikere feil kan betraktes som en kostnad. Hvis vi skal bruke prediksjonenen til noe i praksis, så skal det jo få konsekvenser på en eller annen måte. Det kan innebære at man setter i verk tiltak som er unødvendige - eller ikke setter i verk tiltak der man burde gjort det.
Et sentralt spørsmål er derfor om begge typer feil er like viktig eller alvorlig. Noen ganger er det det, men det bør man ta stilling til helt konkret i det enkelte tilfellet. Det er ikke åpenbart hvem som har kompetanse til å vurdere dette. Det kan kreves inngående fagkunnskap for å gjøre en riktig vurdering, eller det kan være politiske prioriteringer, økonomiske forhold, rettferdighetsvurderinger osv. Det er i hvert fall ikke bare opp til forskeren eller IT-personalet å vurdere.
Dette kan koke ned til helt konkret vurdering av hvor mange falske positive er du villig til å godta per falske negative. Et konkret eksempel er studien til Berk et al (2016) av menn som er arrestert for vold i nære relasjoner. Problemstillingen er hvem skal i arrest frem til saken kommer opp og hvem skal løslates mot kausjon. Prediksjonen er da hvem som vil begå ny voldshandling mot partner. Forholdet mellom TN og FN oversettes konkret til hvor mange mistenkte skal sitte unødig i fengsel (dvs. falske positive) mot hvor mange partnere skal unødig utsettes for ny voldshendelse (dvs. falske negative)? I nevnte studie har noen “stakeholders” landet på at falske negative er vesentlig mer alvorlig enn falske positive. Prediksjonsmodellen utformes så for å reflektere akkurat det.
1.5 Rettferdighet og rimelighet
I diskusjoner av anvendelser av maskinlæring står rettferdighet helt sentralt. Men det er ikke alltid like klart hva dette egentlig betyr utover at det er forskjellsbehandling. Tross alt er hele formålet med prediksjon å nettopp forskjellsbehandle, eller målrette som det også kan kalles. Rettferdighet kommer inn på flere nivåer, fra det helt prinsippielle ved å la data og datamaskiner ha betydning for avgjørelser til det helt konkrete til hvordan feilratene bør se ut. Vurdering av asymetriske kostnader er åpenbart også et rettferdighetsspørsmål med etiske implikasjoner. En variant er at disse feilratene kan se forskjellige ut på tvers av undergrupper.
Hvilke konsekvenser som er akseptable er viktig. Men det er også viktig før man bygger modellen. Software kommer med default innstillinger, men det betyr jo ikke at de er “nøytrale”. Resultatene kan til en viss grad styres, så det må man rett og slett gjøre.
1.5.1 Fundamentale skjevheter i data
Siden maskinlæring baserer seg på å lære av tilgjengelige data for å benytte det på nye tilfeller spiller det vesentlig rolle hvordan de opprinnelige dataene ble generert i utgangspunktet.
Et velkjent eksempel er hvordan Amazon besluttet å slutte å bruke en algoritme for rekruttering fordi den systematisk valgte bort kvinner. Grunnen til at algoritmen gjorde dette var så enkelt som at dataene den var trent opp på var mannsdominert. Algoritmen hadde altså primært tilgang til informasjon om hvilke egenskaper som kjennetegnet talentfulle mannlige kandidater, som altså kan være forskjellige fra talentfulle kvinnelige kandidater.
Når man skal ta en algoritme i bruk er det derfor helt avgjørende at man kan forsvare bruken av de dataene algoritmen er trent på. Kjente skjevheter kan i prinsippet motarbeides ved tuning (dette kommer vi tilbake til), men det er vanskelig å garantere at det er skjevheter man ikke har tenkt på.
Berk, Richard. 2016. Statistical Learning from a Regression Perspective. USA: Springer.
Source Code
# Introduksjon til maskinlæringTemaet er maskinlæring generelt og datadrevne beslutninger. Vi kommer inn på flere av temaene som vil behandles grundigere gjennom kurset.## Noen innledende metodiske begrepI standard samfunnsvitenskapelige metodekurs lærer man først og fremst teknikker for å beskrive data og statistisk inferens for å beskrive usikkerheten rundt estimatene. Avhengig av studiets øvrige design kan resultatene tolkes kausalt og/eller generalisere til en nærmere veldefinert populasjon [@berk2016a].Usikkerhet beskrives typisk ved hjelp standardfeil, p-verdier og konfidensintervall tilhørende spesifikke statistiske tester. Dette innebærer at man bruker statistiske *modeller* for hvordan resultatene ville sett ut under spesifikke forutsetninger. Samplingfordelinger som normalfordelingen og en del andre tilsvarende fordelinger er derfor sentralt. De fleste teknikkene vi skal bruke i dette kurset er *ikke* statistiske modeller i samme forstand og det er ingen antakelser om samplingfordelinger. Standardfeil og konfidensintervall kan derfor ikke regnes ut. Usikkerhet og hvem resultatene gjelder for er også relevante for maskinlæring, men ikke helt på samme måte.## Forklaringer og prediksjonerVi er i liten grad interessert i regresjonskoeffisienter, $\beta$, og tolkning av denne. Derimot er vi interessert i det predikerte utfallet $\hat{y}_i$.## Overfitting: training og testing datasetNår man tilpasser en statistisk modell eller algoritme til data så er det lett å tenke at modellen bør gjenspeile dataene så godt som mulig. Samtidig sies det ofte at modellene skal være så enkle som tilrådelig. En mer komplisert modell vil jo være i stand til å tilpasses dataene i større grad, så hvordan avveie dette?Spørsmålet nå er ikke hvor godt modellen passer til disse dataene, men hvordan den passer til *nye* data! Altså *fremtidige* data eller fremtidig situasjon. La oss si at vi har et datasett som kan plottes om følger:```{r}#| eval: true#| code-fold: false#| echo: true#| warning: false #| message: falselibrary(tidyverse)n <-10beta <-1set.seed(42)x <-round(20+runif(n)*50, digits =1)y <-1+ beta*x +rnorm(n)*10df <-data.frame(x = x, y = y) %>%mutate(d =case_when(x <50~0, x <56~1, TRUE~2) %>%as_factor())g1 <-ggplot(df, aes(x = x, y = y)) +geom_point() g1```Vi kunne her tilpasse en enkel lineær regresjonsmodell eller en mer komplisert modell. Resultatet vises i grafen nedenfor.```{r}#| eval: true#| code-fold: false#| echo: true#| warning: false #| message: falseest1 <-lm(y ~ x + x*d, data = df)est2 <-lm(y ~ x, data = df)df_p1 <- df %>%mutate(pred =predict(est1)) %>%mutate(res_pred = y - pred, res_y = y -mean(y))ggplot(df, aes(x = x, y = y)) +geom_point(col ="black") +geom_line(data = df_p1, aes(y = pred), col ="red", linewidth = .7) +stat_smooth(method='lm', formula = y ~ x, se = F, col ="blue", linewidth = .7)```Den kompliserte modellen gir $r^2$ = `r summary(est1)$r.squared` mens den enkle lineære gir $r^2$ = `r summary(est2)$r.squared`.```{r}#| eval: true#| code-fold: false#| echo: true#| warning: false #| message: falsesummary(est1)$r.squaredsummary(est2)$r.squared``````{r}#| eval: true#| code-fold: false#| echo: true#| warning: false #| message: falsex <-round(20+runif(n)*50, digits =1)y <-1+ beta*x +rnorm(n)*10df2 <-data.frame(x = x, y = y)g1 +geom_point(data = df2, col ="blue") +geom_smooth(method = lm, se = F, col ="red")```## Klassifikasjonsusikkerhet - grunnleggende begreperI praksis kommer vi til å fokusere mest på *klassifikasjon*, som altså er når det vi predikerer er en kategorisk variabel. For nye personer vil vi da gjerne predikere hvilken kategori vedkommende tilhører. En variant av dette er å predikere en fremtidig *handling* (slutte i jobb, ikke betale tilbake lån, begå ny kriminalitet etc).### Confusion matrix: riktig og feil klassifiseringNår vi predikerer et kategorisk utfall er det gjerne ett av utfallene vi primært er interessert i. Disse kalles *positive* og de andre er *negative*. Dette har ingenting å gjøre med om utfallet er bra eller dårlig å gjøre. Å predikere en sykdom vil være *positivt* og å være frisk vil være *negativt*. Å ha tilbakefall til kriminalitet vil være *positivt* og lovlydig vil være *negativt*.En *positiv* prediksjon kan da være korrekt eller feil, og disse kalles da henholdsvis *sanne* eller *falske* positive. Tilsvarende kan en negaitv prediksjon være sann eller falsk.<!--# https://tablesgenerator.com/html_tables -->||| **Predikert** |||---------------|-------------|----------------------|----------------------|||| **Negativ** | **Positiv** || **Observert** | **Negativ** | Sanne negative (TN) | Falske positive (FN) ||| **Positiv** | Falske negative (FN) | Sanne positive (TP) |### Asymetriske kostnaderÅ predikere feil kan betraktes som en *kostnad*. Hvis vi skal bruke prediksjonenen til noe i praksis, så skal det jo få konsekvenser på en eller annen måte. Det kan innebære at man setter i verk tiltak som er unødvendige - eller ikke setter i verk tiltak der man burde gjort det.Et sentralt spørsmål er derfor om begge typer feil er like viktig eller alvorlig. Noen ganger er det det, men det bør man ta stilling til helt konkret i det enkelte tilfellet. Det er ikke åpenbart hvem som har kompetanse til å vurdere dette. Det kan kreves inngående fagkunnskap for å gjøre en riktig vurdering, eller det kan være politiske prioriteringer, økonomiske forhold, rettferdighetsvurderinger osv. Det er i hvert fall ikke bare opp til forskeren eller IT-personalet å vurdere.Dette kan koke ned til helt konkret vurdering av hvor mange falske positive er du villig til å godta per falske negative. Et konkret eksempel er studien til Berk et al (2016) av menn som er arrestert for vold i nære relasjoner. Problemstillingen er hvem skal i arrest frem til saken kommer opp og hvem skal løslates mot kausjon. Prediksjonen er da hvem som vil begå ny voldshandling mot partner. Forholdet mellom TN og FN oversettes konkret til hvor mange mistenkte skal sitte unødig i fengsel (dvs. falske positive) mot hvor mange partnere skal unødig utsettes for ny voldshendelse (dvs. falske negative)? I nevnte studie har noen "stakeholders" landet på at falske negative er vesentlig mer alvorlig enn falske positive. Prediksjonsmodellen utformes så for å reflektere akkurat det.## Rettferdighet og rimelighetI diskusjoner av anvendelser av maskinlæring står rettferdighet helt sentralt. Men det er ikke alltid like klart hva dette egentlig betyr utover at det er forskjellsbehandling. Tross alt er hele formålet med prediksjon å nettopp forskjellsbehandle, eller *målrette* som det også kan kalles. Rettferdighet kommer inn på flere nivåer, fra det helt prinsippielle ved å la data og datamaskiner ha betydning for avgjørelser til det helt konkrete til hvordan feilratene bør se ut. Vurdering av asymetriske kostnader er åpenbart også et rettferdighetsspørsmål med etiske implikasjoner. En variant er at disse feilratene kan se forskjellige ut på tvers av undergrupper.Hvilke konsekvenser som er akseptable er viktig. Men det er også viktig *før* man bygger modellen. Software kommer med default innstillinger, men det betyr jo ikke at de er "nøytrale". Resultatene kan til en viss grad styres, så det må man rett og slett gjøre.### Fundamentale skjevheter i dataSiden maskinlæring baserer seg på å lære av tilgjengelige data for å benytte det på nye tilfeller spiller det vesentlig rolle hvordan de opprinnelige dataene ble generert i utgangspunktet.Et velkjent eksempel er hvordan [Amazon besluttet å slutte å bruke en algoritme for rekruttering fordi den systematisk valgte bort kvinner](https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G). Grunnen til at algoritmen gjorde dette var så enkelt som at dataene den var trent opp på var mannsdominert. Algoritmen hadde altså primært tilgang til informasjon om hvilke egenskaper som kjennetegnet talentfulle *mannlige* kandidater, som altså kan være forskjellige fra talentfulle *kvinnelige* kandidater.Når man skal ta en algoritme i bruk er det derfor helt avgjørende at man kan forsvare bruken av de dataene algoritmen er trent på. Kjente skjevheter kan i prinsippet motarbeides ved *tuning* (dette kommer vi tilbake til), men det er vanskelig å garantere at det er skjevheter man *ikke* har tenkt på.