Rows: 4,127
Columns: 9
$ io_nr <dbl> 3, 4, 5, 8, 11, 12, 13, 14, 16, 17, 18, 19, 20, 21, 22, 23, 2…
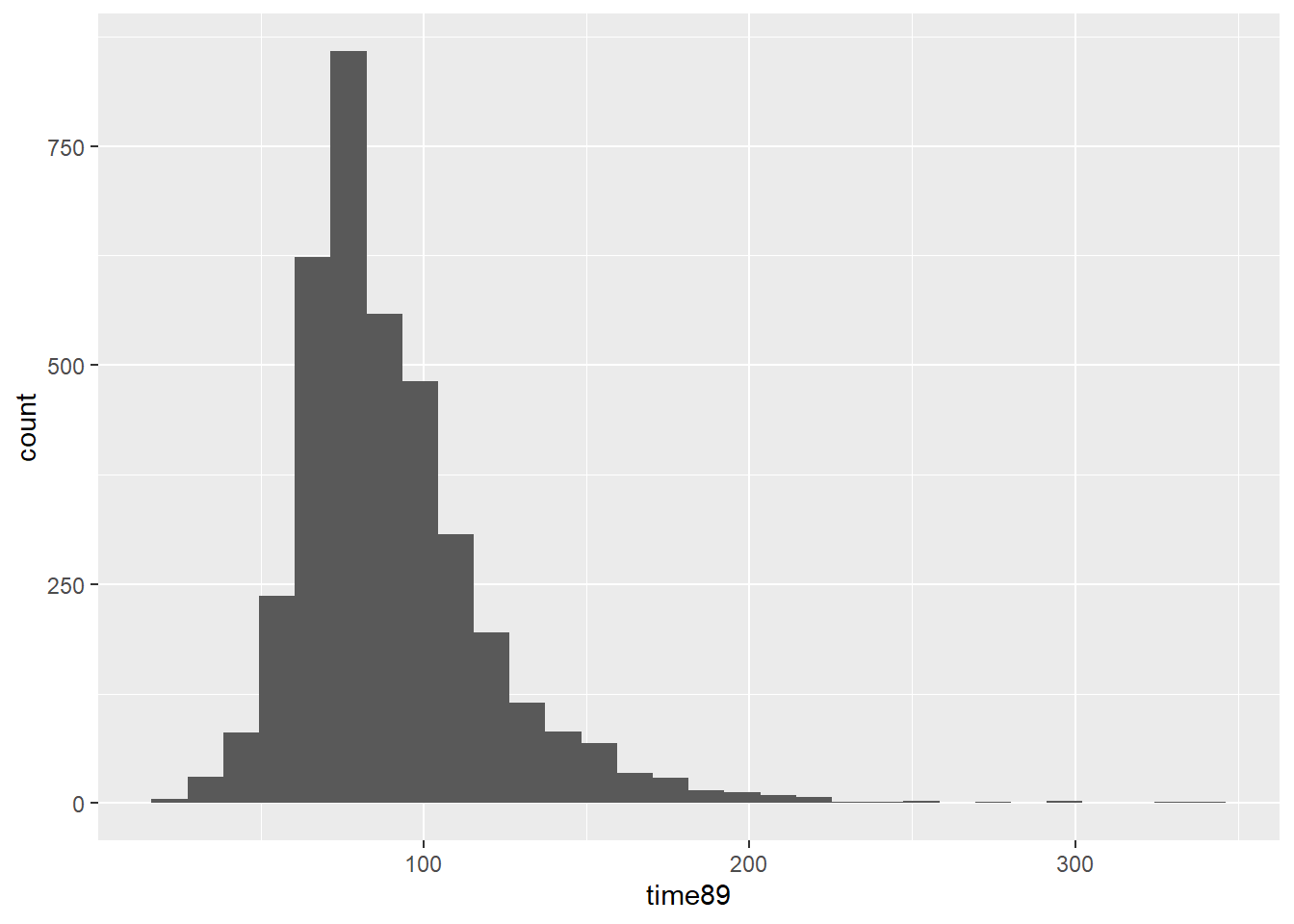
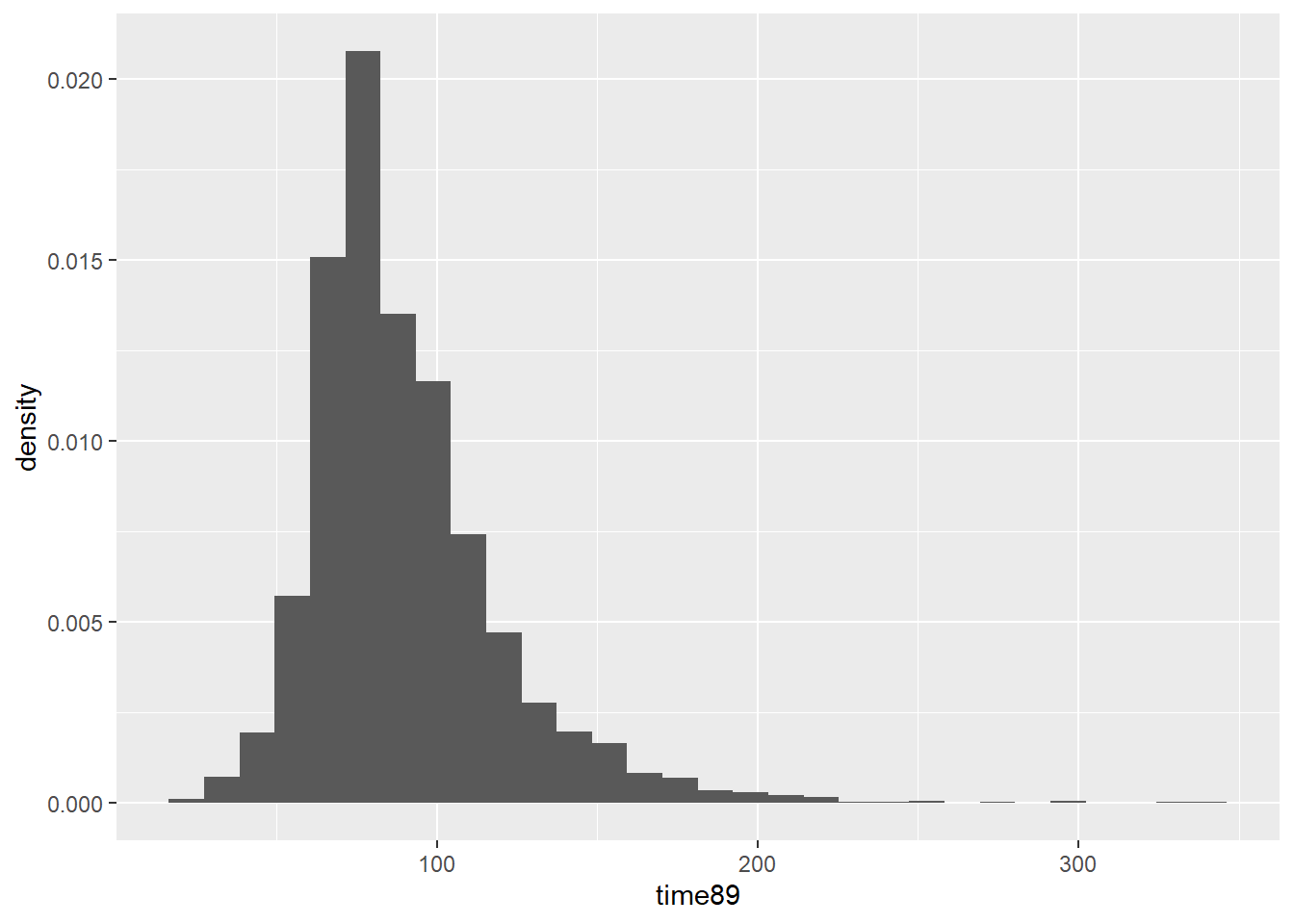
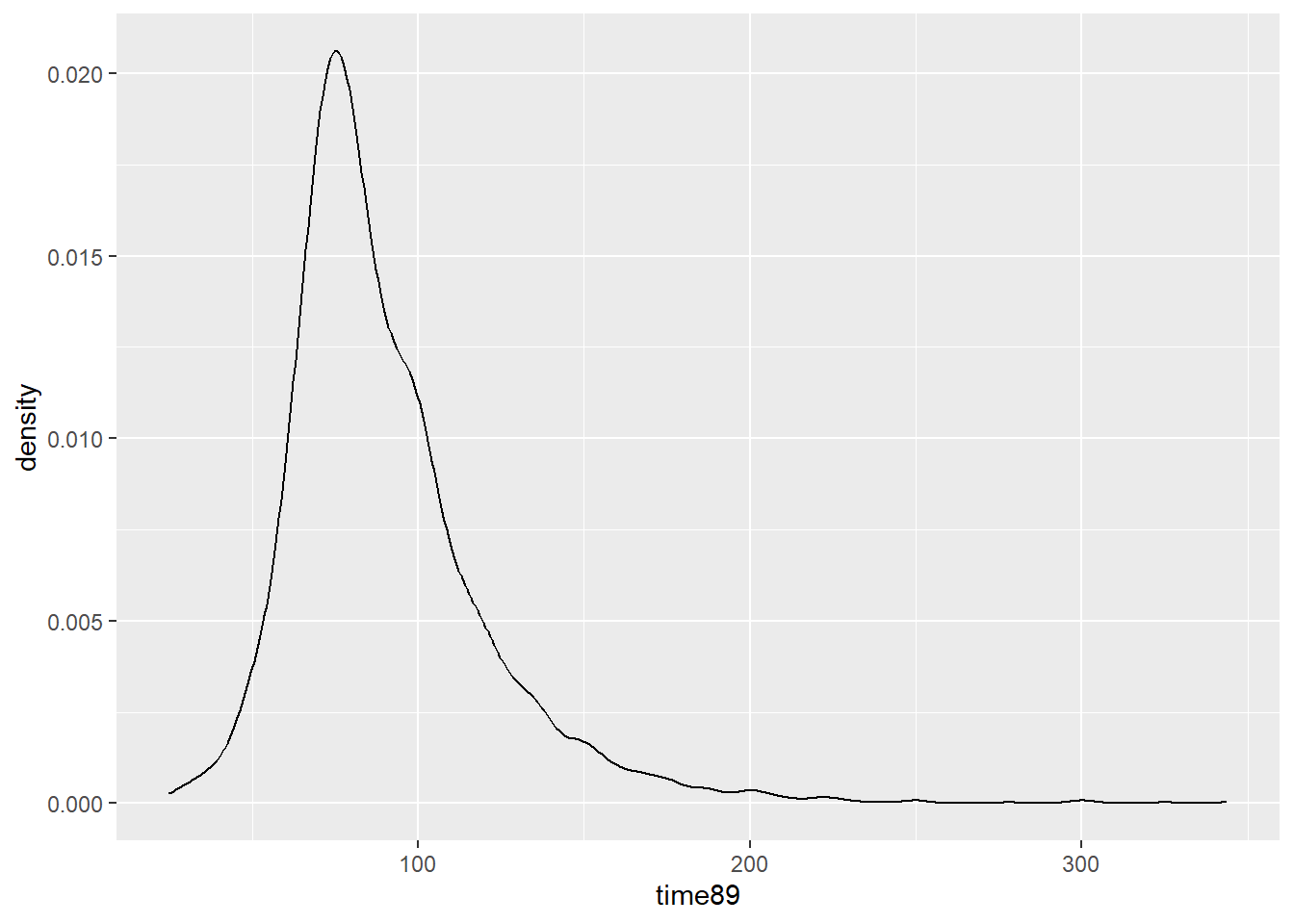
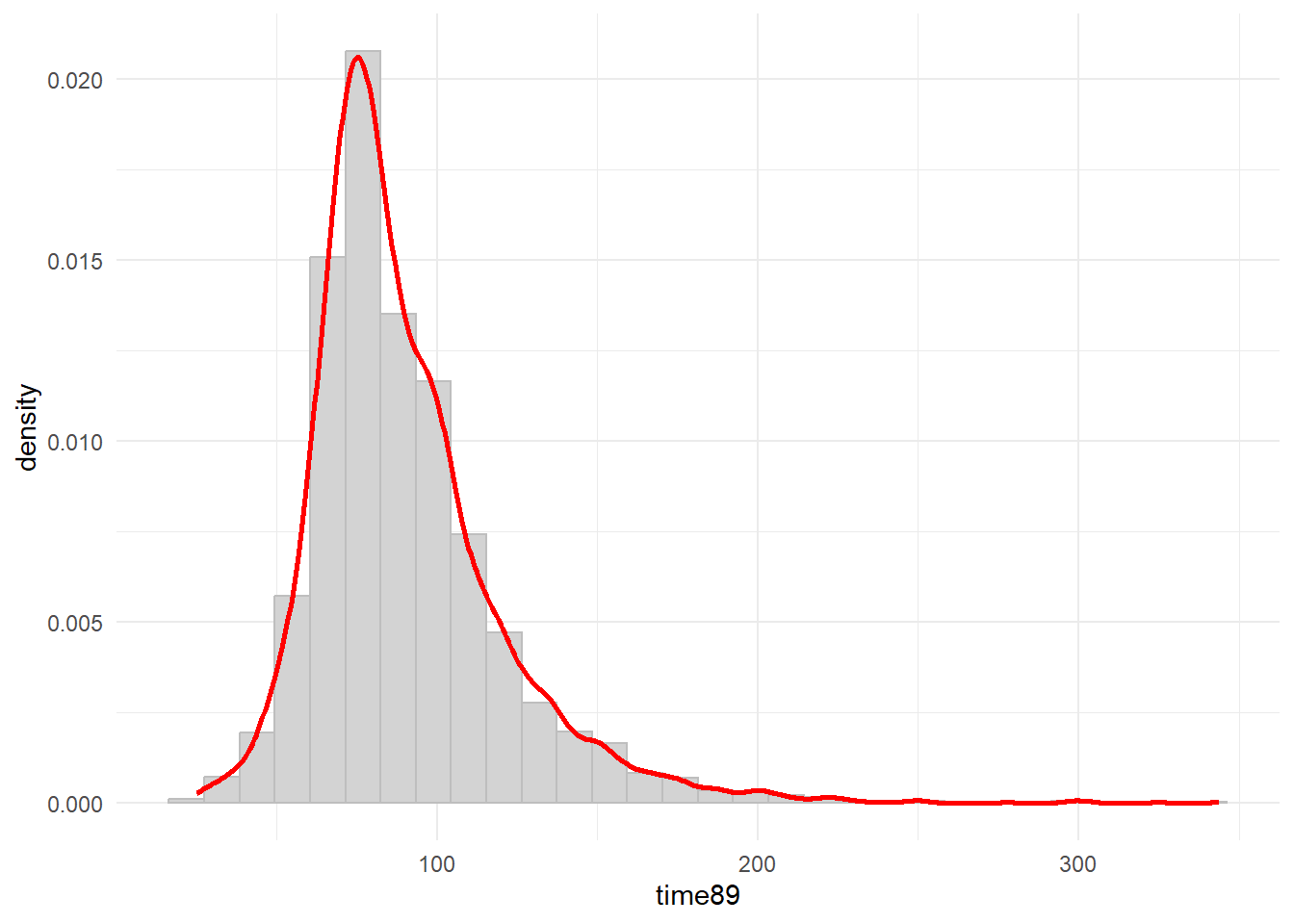
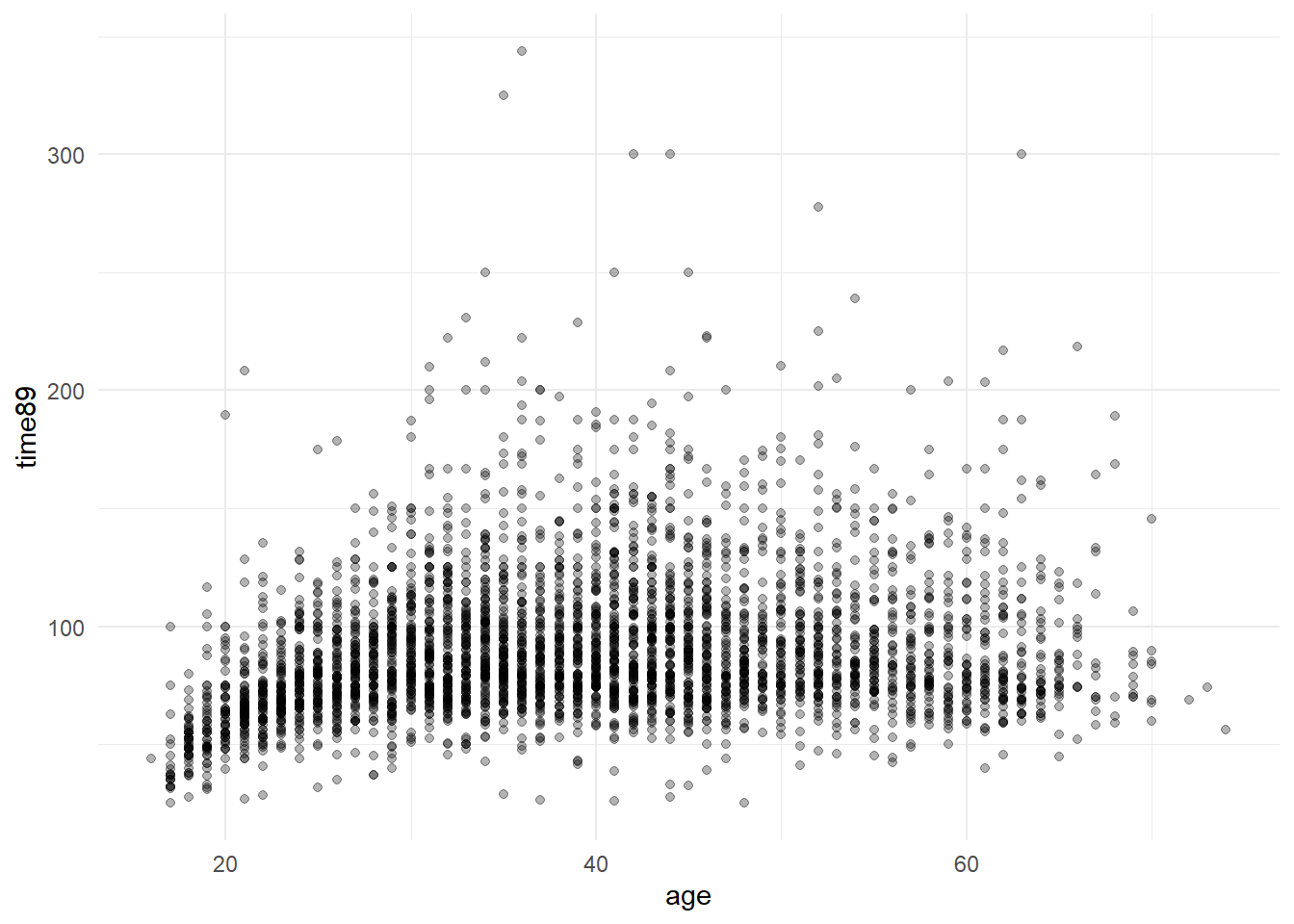
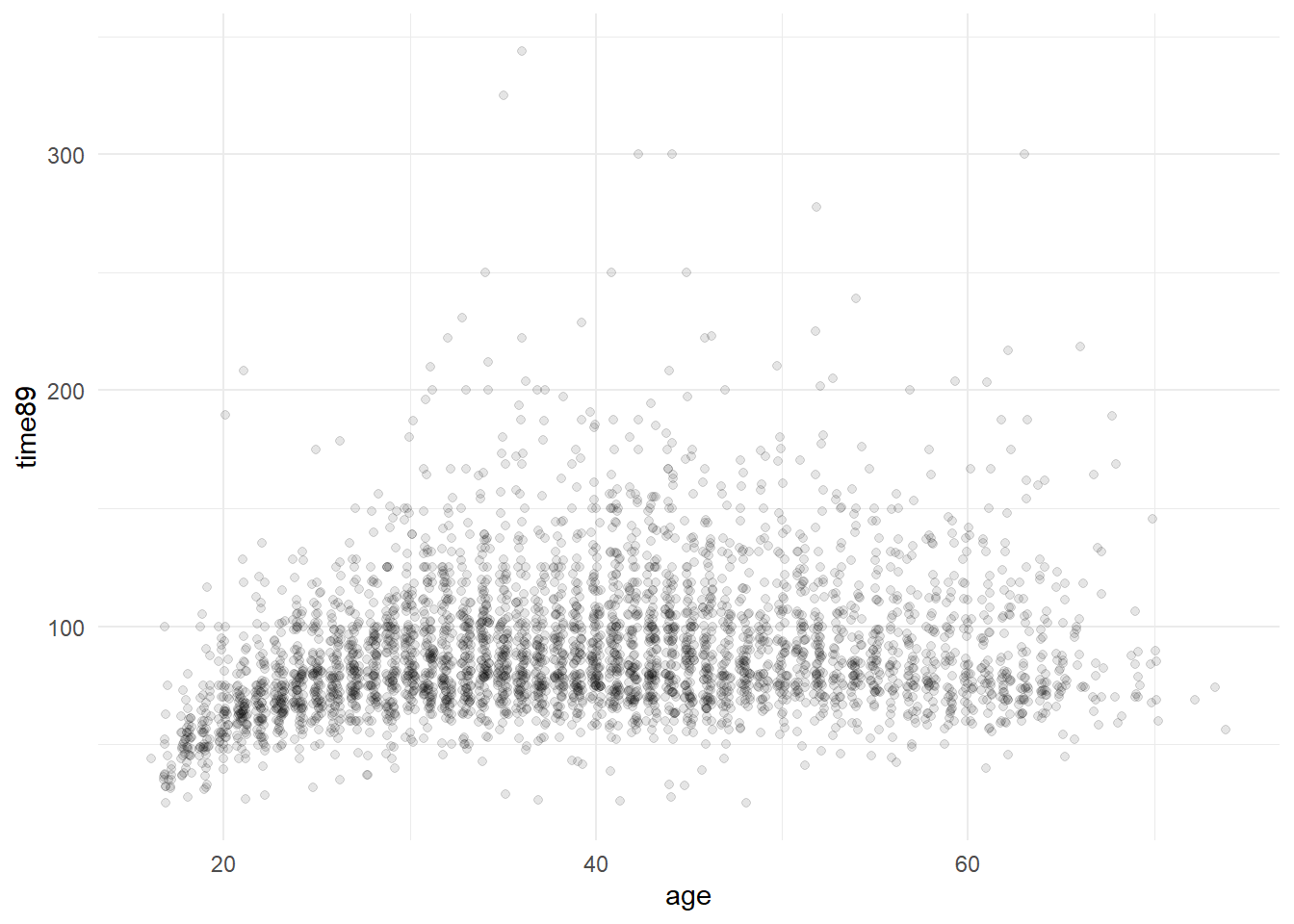
$ time89 <dbl> 62.00000, NA, 91.32895, 84.23913, 90.42553, 103.28947, 75.000…
$ ed <dbl> 0, 1, 3, 5, 3, 1, 1, 7, 3, 9, 0, 9, 1, 3, 9, 3, 0, 3, 1, 3, 3…
$ age <dbl> 58, 24, 44, 46, 40, 36, 31, 31, 26, 29, 54, 58, 25, 25, 56, 5…
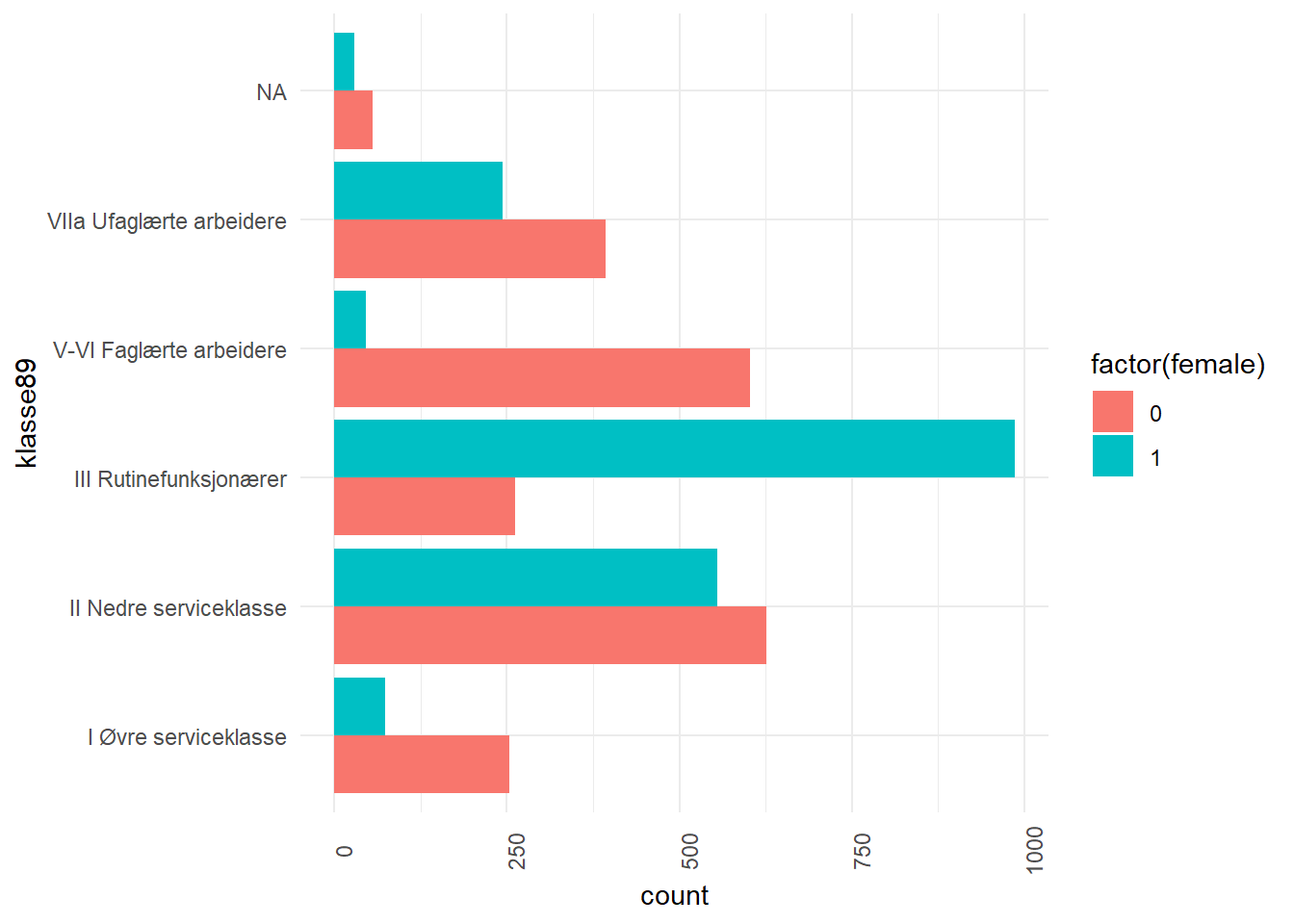
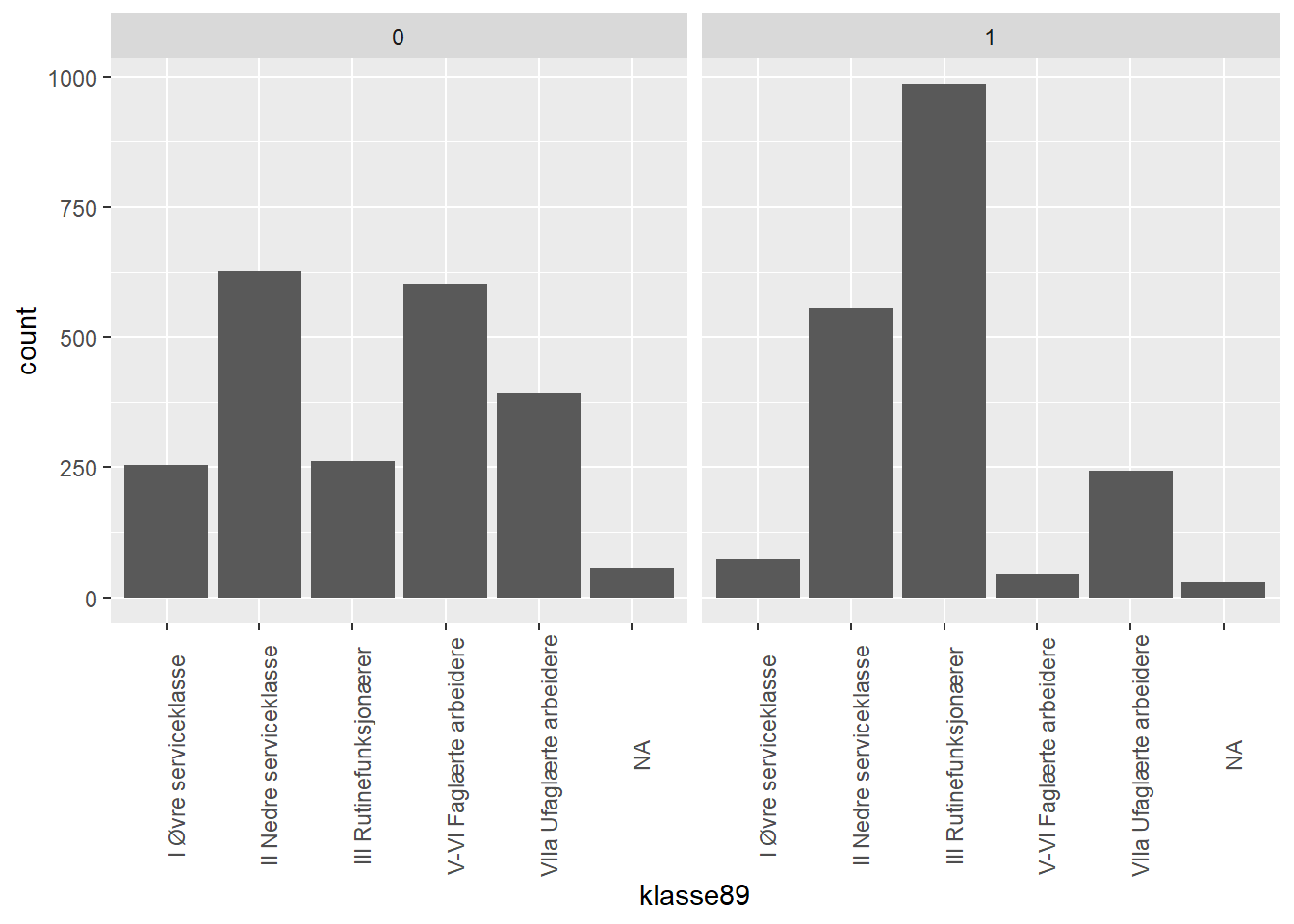
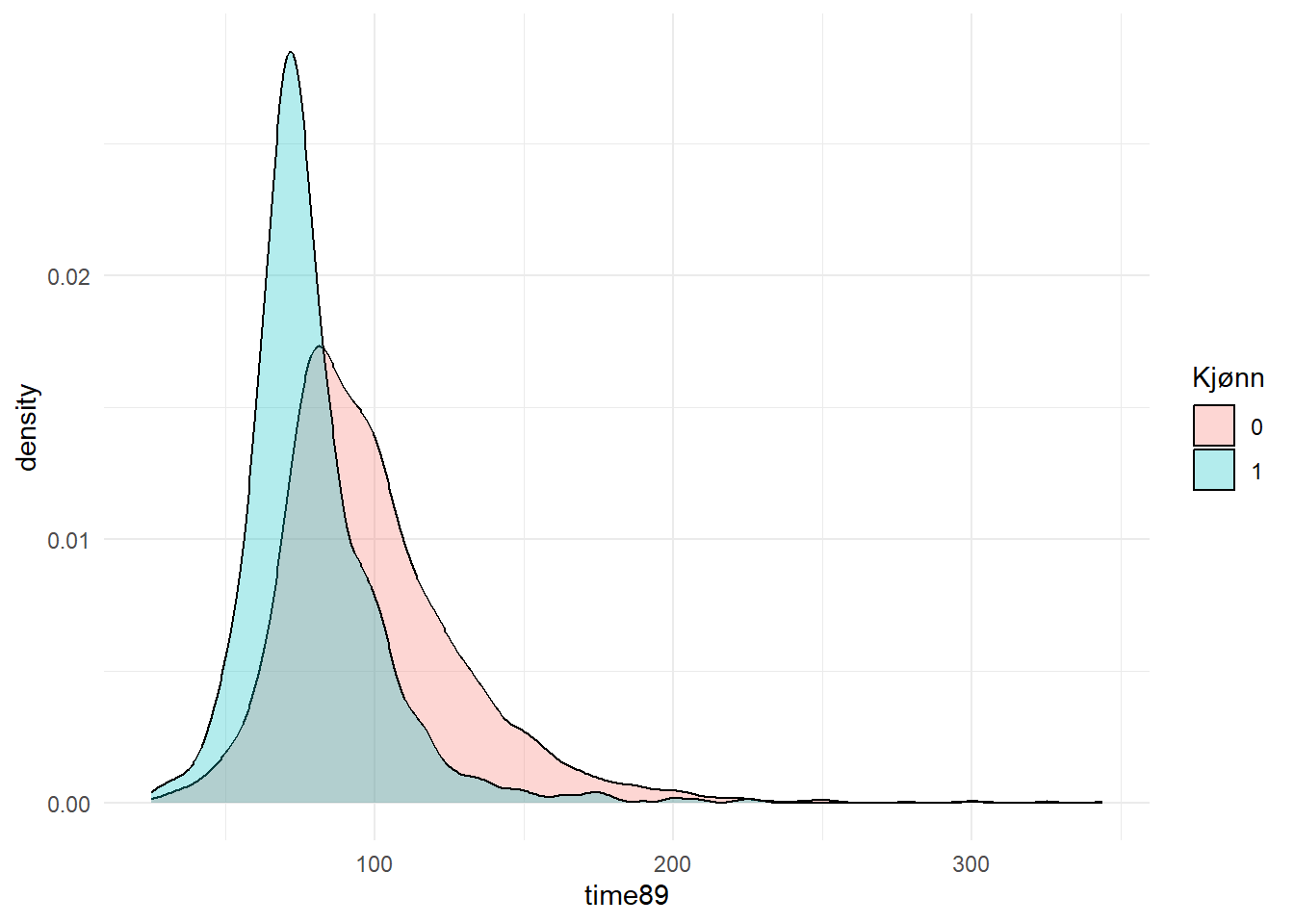
$ female <dbl> 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1…
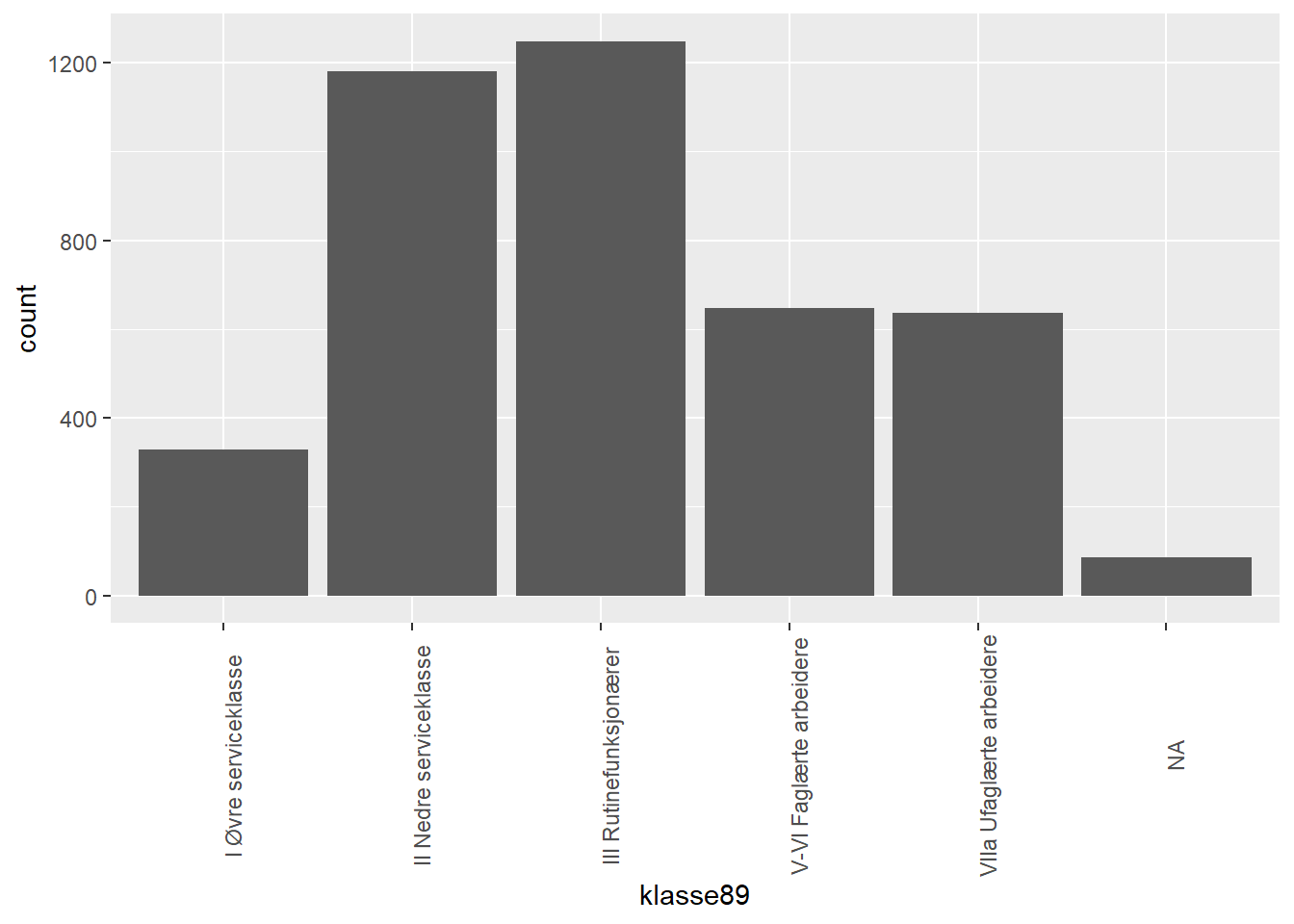
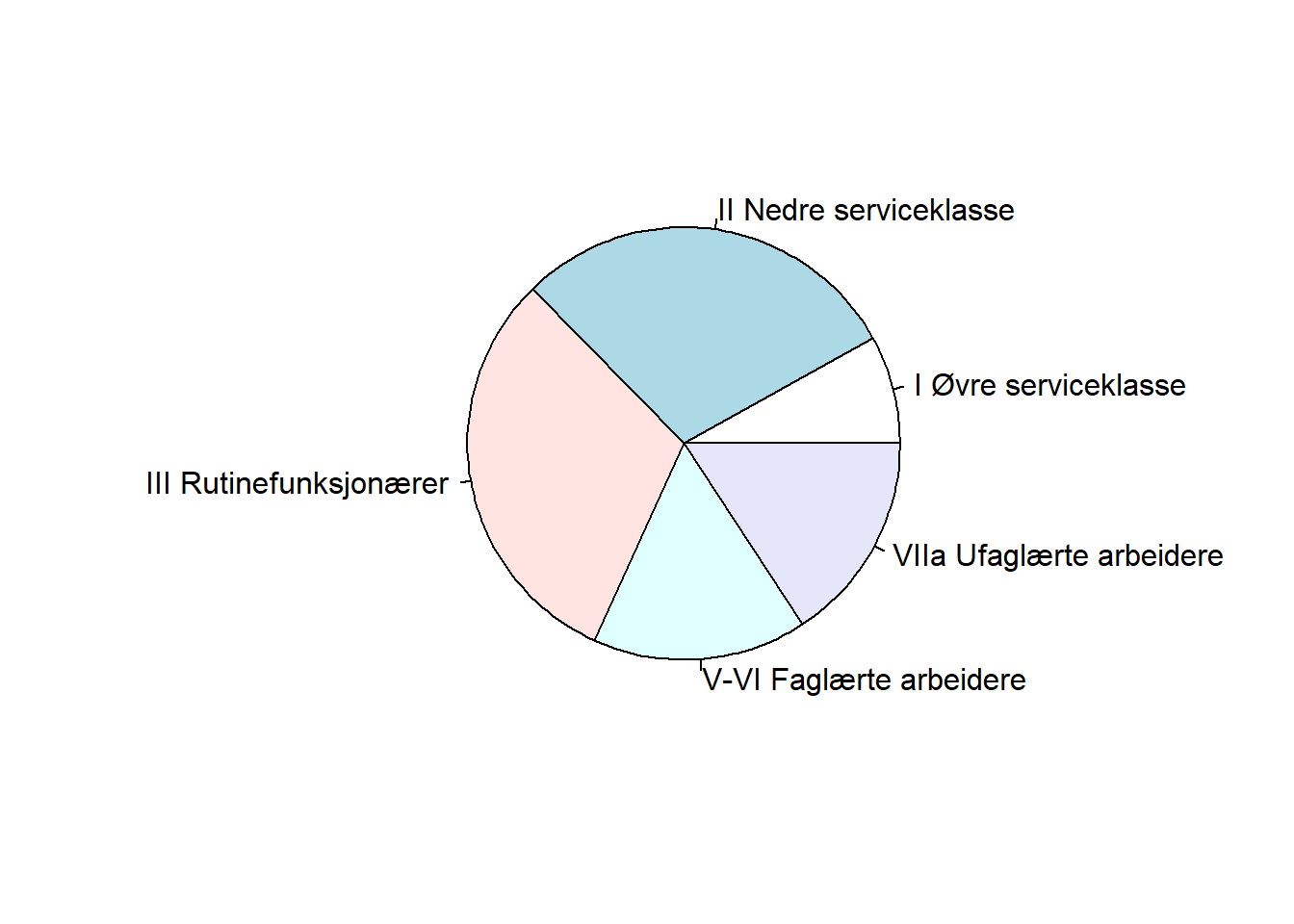
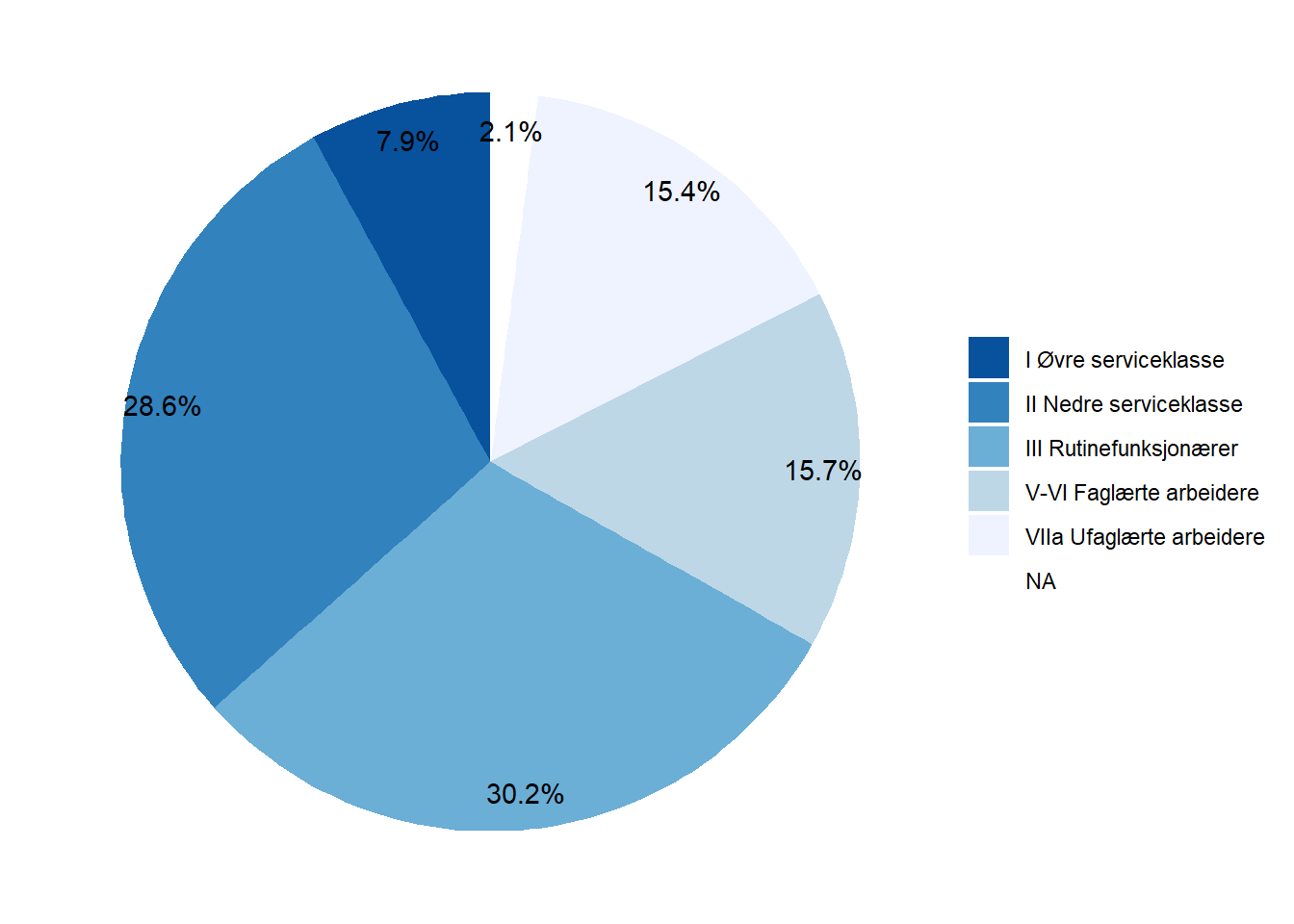
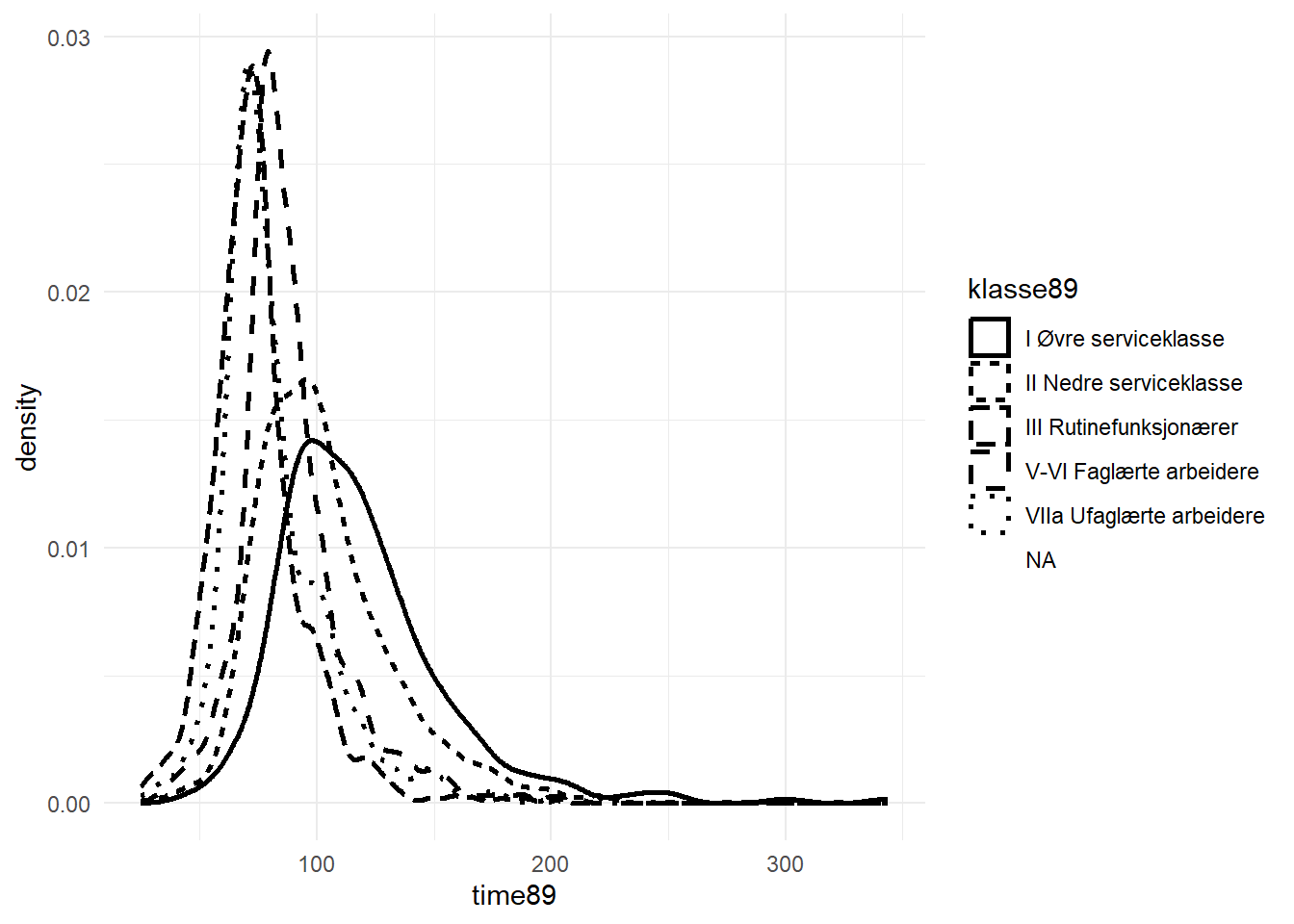
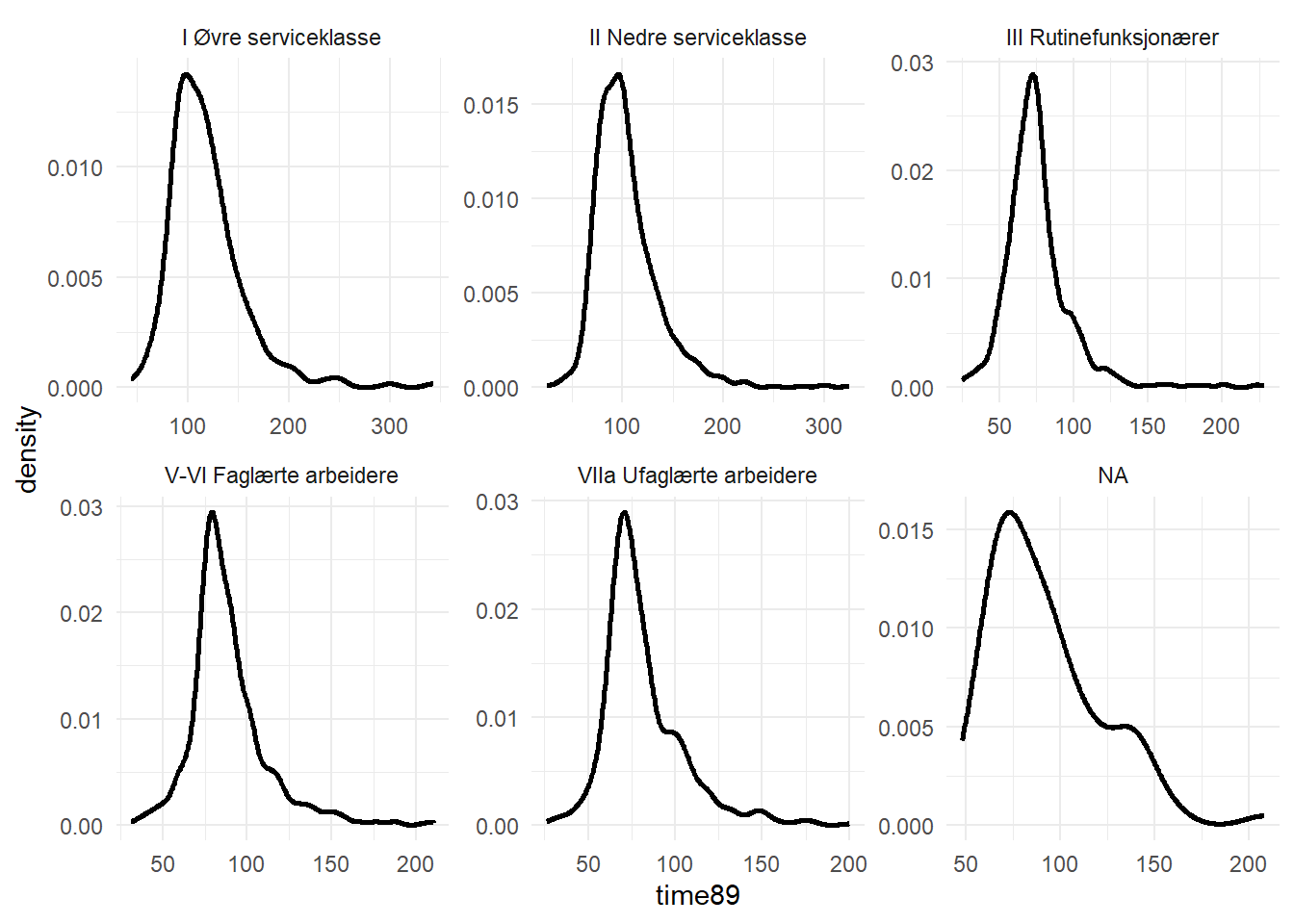
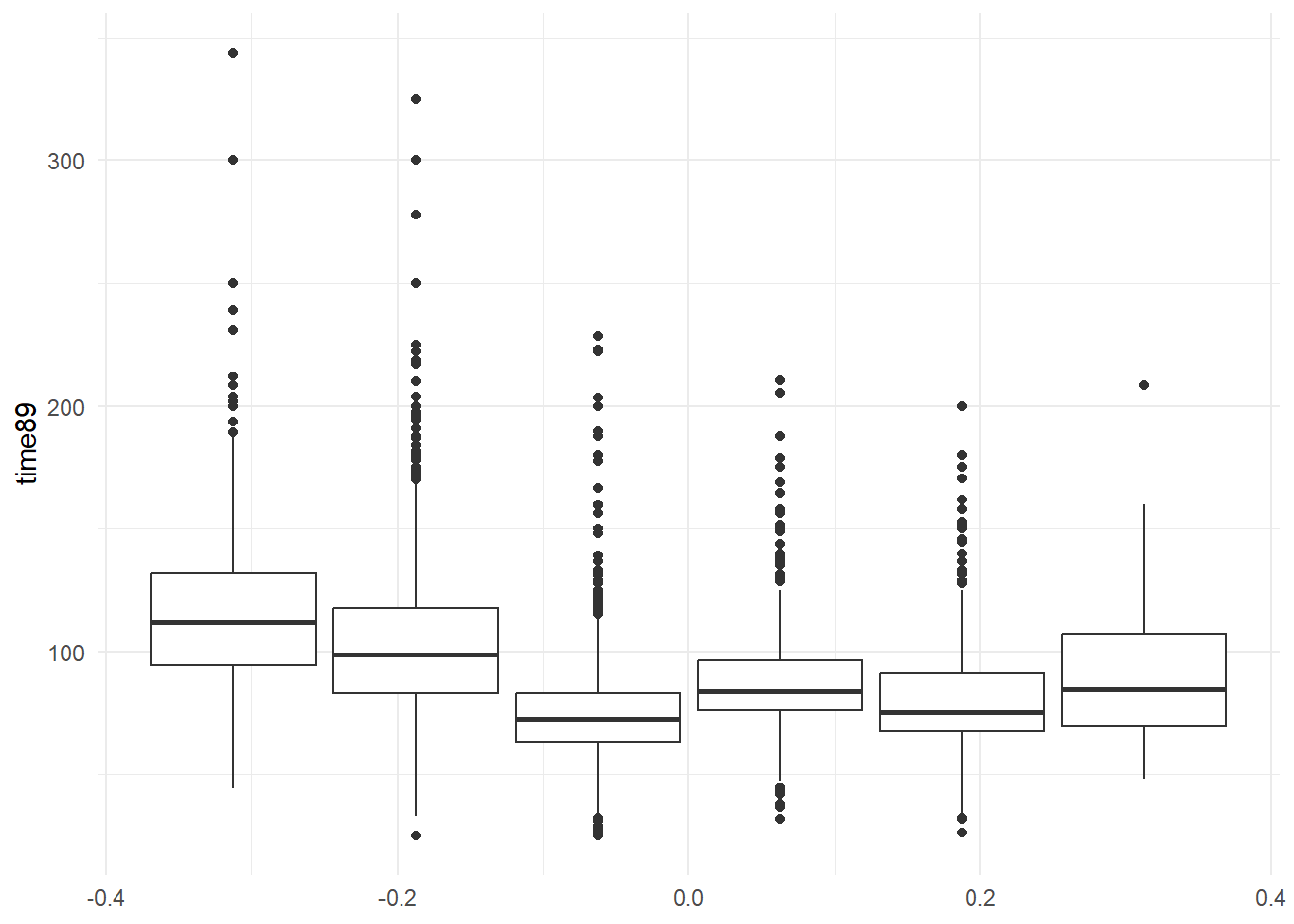
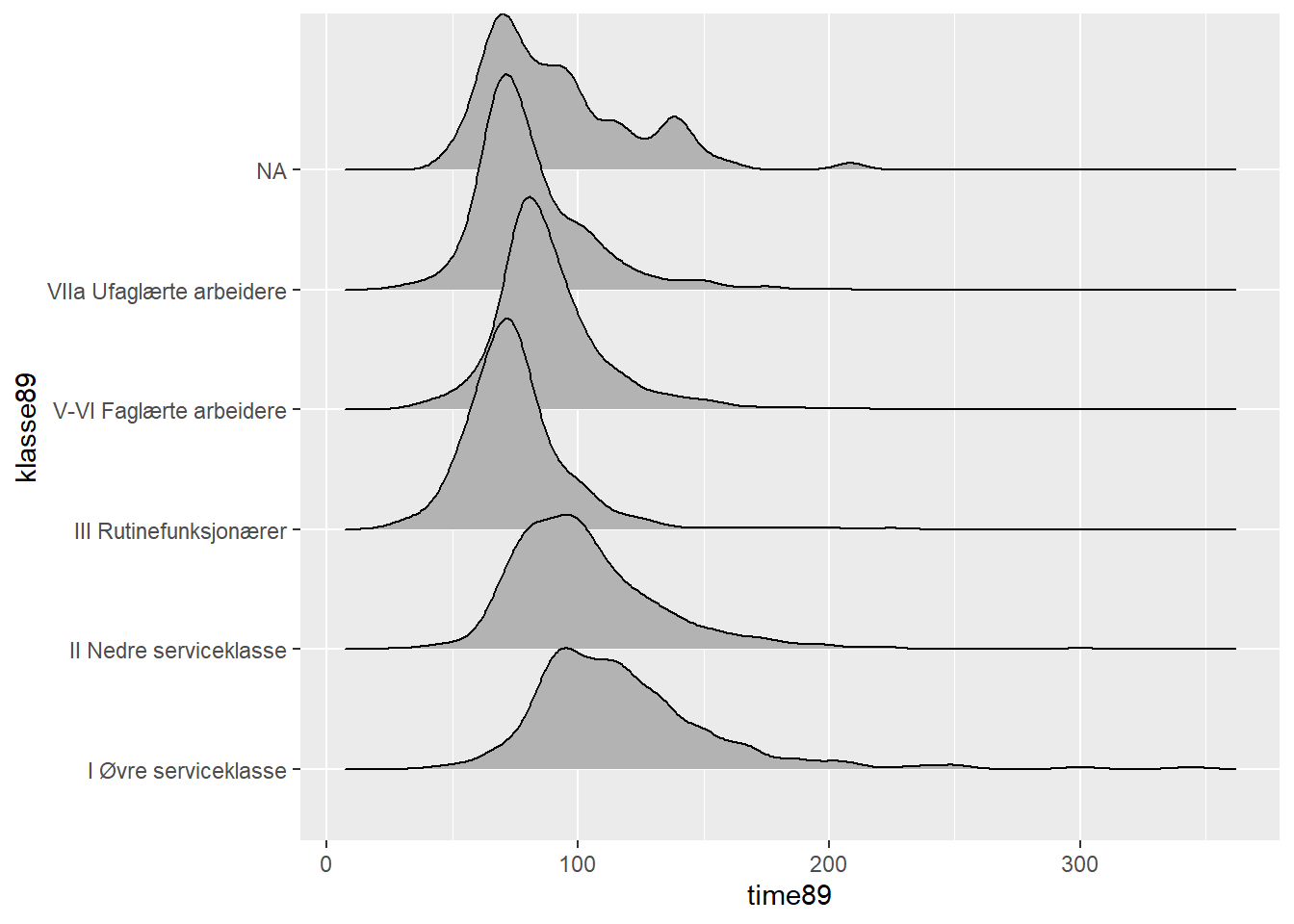
$ klasse89 <fct> III Rutinefunksjonærer, VIIa Ufaglærte arbeidere, II Nedre se…
$ promot <fct> NEI, JA, JA, NEI, NEI, NEI, NEI, NEI, JA, NEI, JA, JA, NEI, J…
$ fexp <dbl> 1.0, 0.3, 1.9, 0.3, 1.0, 1.2, 0.1, 0.4, 0.2, 0.3, 3.5, 3.1, 0…
$ private <fct> Public, Private, Private, Public, Private, Public, Public, Pr…